Results for “Tests” 772 found
Friday assorted links
1. Comparative data on Australian shepherds and other breeds.
2. New paper on Hayek and Schmitt.
3. Zhengdong Wang starts by surveying the year in AI…
4. David Brooks, The Sidney Awards (NYT).
5. Third Triple Crown for Magnus.
6. How is GPT-3 doing on IQ tests?
7. Are Millennials political different and will not age into conservatism?
Does reducing lead exposure limit crime?
These results seem a bit underwhelming, and furthermore there seems to be publication bias, this is all from a recent meta-study on lead and crime. Here goes:
Does lead pollution increase crime? We perform the first meta-analysis of the effect of lead on crime by pooling 529 estimates from 24 studies. We find evidence of publication bias across a range of tests. This publication bias means that the effect of lead is overstated in the literature. We perform over 1 million meta-regression specifications, controlling for this bias, and conditioning on observable between-study heterogeneity. When we restrict our analysis to only high-quality studies that address endogeneity the estimated mean effect size is close to zero. When we use the full sample, the mean effect size is a partial correlation coefficient of 0.11, over ten times larger than the high-quality sample. We calculate a plausible elasticity range of 0.22-0.02 for the full sample and 0.03-0.00 for the high-quality sample. Back-ofenvelope calculations suggest that the fall in lead over recent decades is responsible for between 36%-0% of the fall in homicide in the US. Our results suggest lead does not explain the majority of the large fall in crime observed in some countries, and additional explanations are needed.
Here is one image from the paper:

The authors on the paper are Anthony Higney, Nick Hanley, and Mirko Moroa. I have long been agnostic about the lead-crime hypothesis, simply because I never had the time to look into it, rather than for any particular substantive reason. (I suppose I did have some worries that the time series and cross-national estimates seemed strongly at variance.) I can report that my belief in it is weakening…
In-Person Schooling and Youth Suicide
School attendance, possibly through mechanisms of status competition and bullying, seems to raise the rate of youth suicide:
This study explores the effect of in-person schooling on youth suicide. We document three key findings. First, using data from the National Vital Statistics System from 1990-2019, we document the historical association between teen suicides and the school calendar. We show that suicides among 12-to-18-year-olds are highest during months of the school year and lowest during summer months (June through August) and also establish that areas with schools starting in early August experience increases in teen suicides in August, while areas with schools starting in September don’t see youth suicides rise until September. Second, we show that this seasonal pattern dramatically changed in 2020. Teen suicides plummeted in March 2020, when the COVID-19 pandemic began in the U.S. and remained low throughout the summer before rising in Fall 2020 when many K-12 schools returned to in-person instruction. Third, using county-level variation in school reopenings in Fall 2020 and Spring 2021—proxied by anonymized SafeGraph smartphone data on elementary and secondary school foot traffic—we find that returning from online to in-person schooling was associated with a 12-to-18 percent increase teen suicides. This result is robust to controls for seasonal effects and general lockdown effects (proxied by restaurant and bar foot traffic), and survives falsification tests using suicides among young adults ages 19-to-25. Auxiliary analyses using Google Trends queries and the Youth Risk Behavior Survey suggests that bullying victimization may be an important mechanism.
That is from a new NBER working paper by Benjamin Hansen, Joseph J. Sabia, and Jessamyn Schaller. I am reminded of my earlier Bloomberg column on Covid and school reopening.
Why did China do such a flip-flop on Covid?
After the so-called “Zero Covid” experiment, China now reports that 37 million people are being infected each day. What ever happened to the Golden Mean? Why not move smoothly along a curve? Even after three years’ time, it seems they did little to prep their hospitals. What are some hypotheses for this sudden leap from one corner of the distribution to the other?
1. The Chinese people already were so scared of Covid, the extreme “no big deal” message was needed to bring them around to a sensible middle point. After all, plenty of parts of China still are seeing voluntary social distancing.
2. For Chinese social order, “agreement” is more important than “agreement on what.” And agreement is easiest to reach on extreme, easily stated and explained policies. Zero Covid is one such policy, “let it rip” is another. In the interests of social stability China, having realized its first extreme message was no longer tenable, has decided to move to the other available simple, extreme message. And so they are letting it rip.
3. The Chinese elite ceased to believe in the Zero Covid policy even before the protests spread to such an extreme. But it was not possible to make advance preparations for any alternative policy. Thus when Zero Covid fell away, there was a vacuum of sorts and that meant a very loose policy of “let it rip.”
4. After three years of Zero Covid hardship, the Chinese leadership feels the need to “get the whole thing over with” as quickly as possible.
To which extent might any of these be true? What else?
The FDA’s Lab-Test Power Grab
The FDA is trying to gain authority over laboratory developed tests (LDTs). It’s a bad idea. Writing in the WSJ, Brian Harrison, who served as chief of staff at the U.S. Department of Health and Human Services, 2019-2021 and Bob Charrow, who served as HHS general counsel, 2018-2021, write:
We both were involved in preparing the federal Covid-19 public-health emergency declaration. When it was signed on Jan. 31, 2020, the intent was to cut red tape and maximize regulatory flexibility to allow a nimble response to an emerging pandemic.
Unknown to us, the next day the FDA went in the opposite direction: It issued a new requirement that labs stop testing for Covid-19 and first apply for FDA authorization. At that time, LDTs were the only Covid tests the U.S. had, and many were available and ready to be used in labs around the country. But since the process for emergency-use authorization was extremely burdensome and slow—and because, as we and others in department leadership learned, it couldn’t process applications quickly—many labs stopped trying to win authorization, and some pleaded for regulatory relief so they could test.
Through this new requirement the FDA effectively outlawed all Covid-19 testing for the first month of the pandemic when detection was most critical. One test got through—the one developed by the Centers for Disease Control and Prevention—but it proved to be one of the highest-profile testing failures in history because the entire nation was relying on the test to work as designed, and it didn’t.
When we became aware of the FDA’s action, one of us (Mr. Harrison) demanded an immediate review of the agency’s legal authority to regulate these tests, and the other (Mr. Charrow) conducted the review. Based on the assessment, a determination was made by department leadership that the FDA shouldn’t be regulating LDTs.
Congress has never expressly given the FDA authority to regulate the tests. Further, in 1992 the secretary of health and human services issued a regulation stating that these tests fell under the jurisdiction of the Centers for Medicare and Medicaid Services, not the FDA. Bureaucrats at the FDA have tried to ignore this rule even though the Supreme Court in Berkovitz v. U.S. (1988) specifically admonished the agency for ignoring federal regulations.
Loyal readers will recall that I covered this issue earlier in Clement and Tribe Predicted the FDA Catastrophe. Clement, the former US Solicitor General under George W. Bush and Tribe, a leading liberal constitutional lawyer, rejected the FDA claims of regulatory authority over laboratory developed tests on historical, statutory, and legal grounds but they also argued that letting the FDA regulate laboratory tests was a dangerous idea. In a remarkably prescient passage, Clement and Tribe (2015, p. 18) warned:
The FDA approval process is protracted and not designed for the rapid clearance of tests. Many clinical laboratories track world trends regarding infectious diseases ranging from SARS to H1N1 and Avian Influenza. In these fast-moving, life-or-death situations, awaiting the development of manufactured test kits and the completion of FDA’s clearance procedures could entail potentially catastrophic delays, with disastrous consequences for patient care.
Clement and Tribe nailed it. Catastrophic delays, with disastrous consequences for patient care is exactly what happened. Thus, Harrison and Charrow are correct, giving the FDA power over laboratory derived tests has had and will have significant costs.
The Great Barrington Plan: Would Focused Protection Have Worked?
A key part of The Great Barrington Declaration was the idea of focused protection, “allow those who are at minimal risk of death to live their lives normally to build up immunity to the virus through natural infection, while better protecting those who are at highest risk.” This was a reasonable idea and consistent with past practices as recommended by epidemiologists. In a new paper, COVID in the Nursing Homes: The US Experience, my co-author Markus Bjoerkheim and I ask whether focused protection could have worked.
Nursing homes were the epicenter of the pandemic. Even though only about 1.3 million people live in nursing homes at a point in time, the death toll in nursing homes accounted for almost 30 per cent of total Covid-19 deaths in the US during 2020. Thus we asked whether focusing protection on the nursing homes was possible. One way of evaluating focused protection is to see whether any type of nursing homes were better than others. In other words, what can we learn from best practices?
The Centers for Medicaire and Medicaid Services (CMS) has a Five-Star Rating system for nursing homes. The rating system is based on comprehensive data from annual health inspections, staff payrolls, and clinical quality measures from quarterly Minimum Data Set assessments. The rating system has been validated against other measures of quality, such as mortality and hospital readmissions. The ratings are pre-pandemic ratings. Thus, the question to ask is whether higher-quality homes had better Covid-19 outcomes? The answer? No.
The following figure shows predicted deaths by 5-star rating. There is no systematic relationship between nursing homes rating and COVID deaths. (In the figure, we control for factors outside of a nursing homes control, such as case prevalence in the local community. But even if you don’t control for other factors there is little to no relationship. See the paper for more.) Case prevalence in the community not nursing home quality determined death rates.
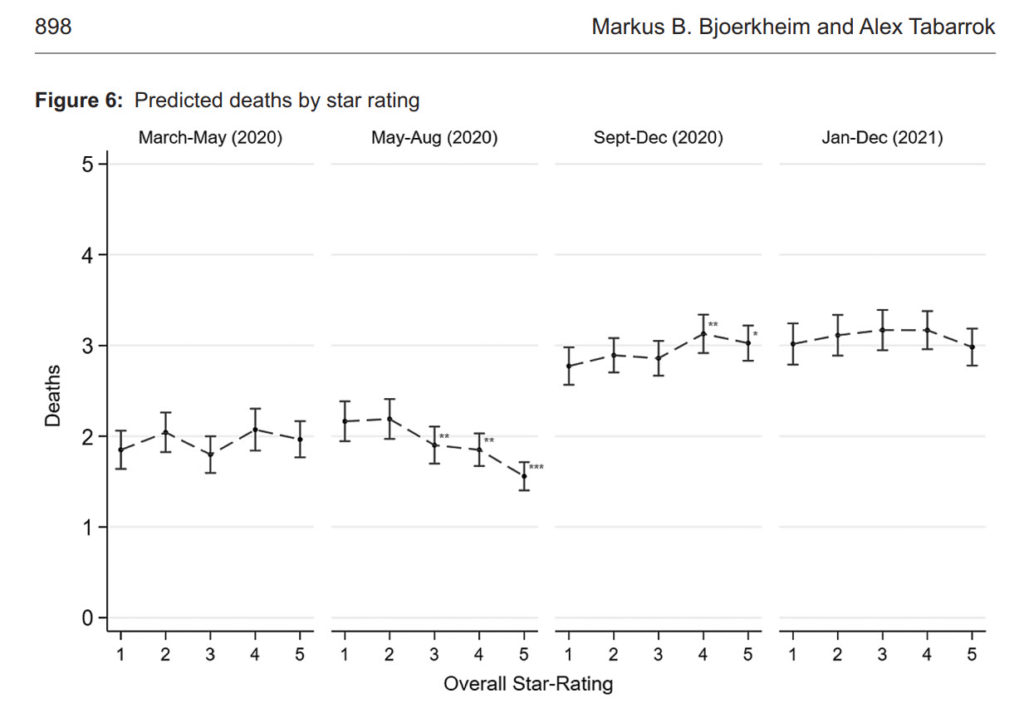
More generally, we do some exploratory data analysis to see whether there were any “islands of protection” in the sea of COVID and the answer is basically no. Some facilities did more rapid tests and that was good but surprisingly (to us) the numbers of rapid tests needed to scale nationally and make a substantial difference in nursing home deaths was far out of sample and below realistic levels.
Finally, keep in mind that the United States did focused protection. Visits to nursing homes were stopped and residents and staff were tested to a high degree. What the US did was focused protection and lockdowns and masking and we still we had a tremendous death toll in the nursing homes. Focused protection without community controls would have led to more deaths, both in the nursing homes and in the larger community. Whether that would have been a reasonable tradeoff is another question but there is no evidence that we could have lifted community controls and also better protected the nursing homes. Indeed, as I pointed out at the time, lifting community controls would have made it much more difficult to protect the nursing homes.
On publication bias in economics, from the comments
What are the politics of ChatGPT?
Rob Lownie claims it is “Left-liberal.” David Rozado applied the Political Compass Test and concluded that ChatGPT is a mix of left-leaning and libertarian, for instance: “anti death penalty, pro-abortion, skeptic of free markets, corporations exploit developing countries, more tax the rich, pro gov subsidies, pro-benefits to those who refuse to work, pro-immigration, pro-sexual liberation, morality without religion, etc.”
He produced this image from the test results:
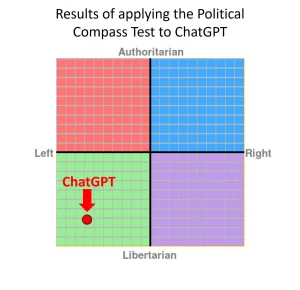
Rozado applied several other political tests as well, with broadly similar results. I would, however, stress some different points. Most of all, I see ChatGPT as “pro-Western” in its perspective, while granting there are different visions of what this means. I also see ChatGPT as “controversy minimizing,” for both commercial reasons but also for simply wishing to get on with the substantive work with a minimum of external fuss. I would not myself have built it so differently, and note that the bias may lie in the training data rather than any biases of the creators.
Marc Andreessen has had a number of tweets suggesting that AI engines will host “the mother of all battles” over content, censorship, bias and so on — far beyond the current social media battles.
The level of censorship pressure that’s coming for AI and the resulting backlash will define the next century of civilization. Search and social media were the opening skirmishes. This is the big one. World War Orwell.
— Marc Andreessen 🇺🇸 (@pmarca) December 5, 2022
I agree.
I saw someone ask ChatGPT if Israel is an apartheid state (I can’t reproduce the answer because right now Chat is down for me — alas! But try yourself.). Basically ChatGPT answered no, that only South Africa was an apartheid state. Plenty of people will be unhappy with that answer, including many supporters of Israel (the moral defense of Israel was, for one thing, not full-throated enough for many tastes). Many Palestinians will object, for obvious reasons. And how about all those Rhodesians who suffered under their own apartheid? Are they simply to be forgotten?
When it comes to politics, an AI engine simply cannot win, or even hold a draw. Yet there is not any simple way to keep them out of politics either. By the way, if you are frustrated by ChatGPT skirting your question, rephrase it in terms of asking it to write a dialogue or speech on a topic, in the voice or style of some other person. Often you will get further that way.
The world hasn’t realized yet how powerful ChatGPT is, and so Open AI still can live in a kind of relative peace. I am sorry to say that will not last for long.
Thursday assorted links
1. Why so few protests in Russia?
2. Did English case law boost the Industrial Revolution?
3. GMU thinkers as religious thinkers, and don’t forget RH…
4. Henry Oliver’s best books of the year list.
5. Building the World Trade Center.
6. Appreciation of James Lovelock.
7. More on Tether risk (WSJ).
8. GMU enters the world of cricket, the Indian century indeed.
Solve for the equilibrium
A Buddhist temple in central Thailand has been left without monks after all of its holy men failed drug tests and were defrocked, a local official said Tuesday.
Four monks, including an abbot, at a temple in Phetchabun province’s Bung Sam Phan district tested positive for methamphetamine on Monday, district official Boonlert Thintapthai told AFP.
The monks have been sent to a health clinic to undergo drug rehabilitation, the official said.
“The temple is now empty of monks and nearby villagers are concerned they cannot do any merit-making,” he said. Merit-making involves worshippers donating food to monks as a good deed.
Boonlert said more monks will be sent to the temple to allow villagers to practice their religious obligations.
Here is the full story, via S.
Sunday assorted links
1. U.S. restrictions on GPU sales to China.
2. Inside (one part of) the pro-natalist movement.
3. What is going on in Quebec’s health care system?
4. Annie Lowery on women in the economics profession.
5. Intentional, or was there a trickster (or Straussian) involved in this one?
6. Thread on the Chinese protests. And ChinaTalk on the China protests.
Why is the New World so dangerous?
I’ve been asking people that question for years, here is the best answer I have found so far:
We argue that cross-national variability in homicide rates is strongly influenced by state history. Populations living within a state are habituated, over time, to settling conflicts through regularized, institutional channels rather than personal violence. Because these are gradual and long-term processes, present-day countries composed of citizens whose ancestors experienced a degree of “state-ness” in previous centuries should experience fewer homicides today. To test this proposition, we adopt an ancestry-adjusted measure of state history that extends back to 0 CE. Cross-country analyses show a sizeable and robust relationship between this index and lower homicide rates. The result holds when using various measures of state history and homicide rates, sets of controls, samples, and estimators. We also find indicative evidence that state history relates to present levels of other forms of personal violence. Tests of plausible mechanisms suggest state history is linked to homicide rates via the law-abidingness of citizens. We find less support for alternative channels such as economic development or current state capacity.
That is from a new paper by John Gerring and Carl Henrik Knutsen. It is also consistent with so much of East Asia having very low murder rates. Via the excellent Kevin Lewis.
A Big and Embarrassing Challenge to DSGE Models
Dynamic stochastic general equilibrium (DSGE) models are the leading models in macroeconomics. The earlier DSGE models were Real Business Cycle models and they were criticized by Keynesian economists like Solow, Summers and Krugman because of their non-Keynesian assumptions and conclusions but as DSGE models incorporated more and more Keynesian elements this critique began to lose its bite and many young macroeconomists began to feel that the old guard just weren’t up to the new techniques. Critiques of the assumptions remain but the typical answer has been to change assumption and incorporate more realistic institutions into the model. Thus, most new work today is done using a variant of this type of model by macroeconomists of all political stripes and schools.
Now along comes two statisticians, Daniel J. McDonald and the acerbic Cosma Rohilla Shalizi. McDonald and Shalizi subject the now standard Smet-Wouters DSGE model to some very basic statistical tests. First, they simulate the model and then ask how well can the model predict its own simulation? That is, when we know the true model of the economy how well can the DSGE discover the true parameters? [The authors suggest such tests haven’t been done before but that doesn’t seem correct, e.g. Table 1 here. Updated, AT] Not well at all.
If we take our estimated model and simulate several centuries of data from it, all in the stationary regime, and then re-estimate the model from the simulation, the results are disturbing. Forecasting error remains dismal and shrinks very slowly with the size of the data. Much the same is true of parameter estimates, with the important exception that many of the parameter estimates seem to be stuck around values which differ from the ones used to generate the data. These ill-behaved parameters include not just shock variances and autocorrelations, but also the “deep” ones whose presence is supposed to distinguish a micro-founded DSGE from mere time-series analysis or reduced-form regressions. All this happens in simulations where the model specification is correct, where the parameters are constant, and where the estimation can make use of centuries of stationary data, far more than will ever be available for the actual macroeconomy.
Now that is bad enough but I suppose one might argue that this is telling us something important about the world. Maybe the model is fine, it’s just a sad fact that we can’t uncover the true parameters even when we know the true model. Maybe but it gets worse. Much worse.
McDonald and Shalizi then swap variables and feed the model wages as if it were output and consumption as if it were wages and so forth. Now this should surely distort the model completely and produce nonsense. Right?
If we randomly re-label the macroeconomic time series and feed them into the DSGE, the results are no more comforting. Much of the time we get a model which predicts the (permuted) data better than the model predicts the unpermuted data. Even if one disdains forecasting as end in itself, it is hard to see how this is at all compatible with a model capturing something — anything — essential about the structure of the economy. Perhaps even more disturbing, many of the parameters of the model are essentially unchanged under permutation, including “deep” parameters supposedly representing tastes, technologies and institutions.
Oh boy. Imagine if you were trying to predict the motion of the planets but you accidentally substituted the mass of Jupiter for Venus and discovered that your model predicted better than the one fed the correct data. I have nothing against these models in principle and I will be interested in what the macroeconomists have to say, as this isn’t my field, but I can’t see any reason why this should happen in a good model. Embarrassing.
Addendum: Note that the statistical failure of the DSGE models does not imply that the reduced-form, toy models that say Paul Krugman favors are any better than DSGE in terms of “forecasting” or “predictions”–the two classes of models simply don’t compete on that level–but it does imply that the greater “rigor” of the DSGE models isn’t buying us anything and the rigor may be impeding understanding–rigor mortis as we used to say.
Addendum 2: Note that I said challenge. It goes without saying but I will say it anyway, the authors could have made mistakes. It should be easy to test these strategies in other DSGE models.
The Invisible Hand Increases Trust, Cooperation, and Universal Moral Action
Montesquieu famously noted that
Commerce is a cure for the most destructive prejudices; for it is almost a general rule, that wherever we find agreeable manners, there commerce flourishes; and that wherever there is commerce, there we meet with agreeable manners.
and Voltaire said of the London Stock Exchange:
Go into the London Stock Exchange – a more respectable place than many a court – and you will see representatives from all nations gathered together for the utility of men. Here Jew, Mohammedan and Christian deal with each other as though they were all of the same faith, and only apply the word infidel to people who go bankrupt. Here the Presbyterian trusts the Anabaptist and the Anglican accepts a promise from the Quaker. On leaving these peaceful and free assemblies some go to the Synagogue and others for a drink, this one goes to be baptized in a great bath in the name of Father, Son and Holy Ghost, that one has his son’s foreskin cut and has some Hebrew words he doesn’t understand mumbled over the child, others go to heir church and await the inspiration of God with their hats on, and everybody is happy.
Commerce makes people traders and by and large traders must be benevolent, agreeable and willing to bargain and compromise with people of different sects, religions and beliefs. Contrary to what one naively might expect, people with more exposure to markets behave more cooperatively and in less nakedly self-interested ways. Similarly, in a letter-return experiment in Italy, Baldassarri finds that market integration increases pro-social behavior towards in and outgroups:
In areas where market exchange is dominant, letter-return rates are high. Moreover, prosocial behavior toward ingroup and outgroup members moves hand in hand, thus suggesting that norms of solidarity extend beyond group boundaries.
Also, contrary to what you may have read about the mythical Wall Street game versus Community game, priming people in the lab with phrases evocative of markets and trade, increases trust.
In a new paper, Gustav Agneman and Esther Chevrot-Bianco test the idea that markets generate more universal behavior. They run their tests in villages in Greenland where some people buy and sell in markets for their primary living while others in the same village still rely for a substantial part of their subsistence on hunting, fishing and personal exchange. They use a dice game in which players report the number of a roll with higher numbers being better for the player. Only the player knows their true roll and there is no way to detect cheaters on an individual basis. In some variants, other people (in-group or out-group) benefit when players report lower numbers. The upshot is that people exposed to market institutions are honest while traditional people cheat. Cheating is only ameliorated in the traditional group when cheating comes at the expense of an in-group (fellow-villager) but not when it comes at the expense of an out-grou member. More generally the authors summarize:
…We conduct rule-breaking experiments in 13 villages across Greenland (N=543), where stark contrasts in market participation within villages allow us to examine the relationship between market participation and moral decision-making holding village-level factors constant. First, we document a robust positive association between market participation and moral behaviour towards anonymous others. Second, market-integrated participants display universalism in moral decision-making, whereas non-market participants make more moral decisions towards co-villagers. A battery of robustness tests confirms that the behavioural differences between market and non-market participants are not driven by socioeconomic variables, childhood background, cultural identities, kinship structure, global connectedness, and exposure to religious and political institutions.
Markets and trade increase trust, cooperation and universal moral action–it is hard to think of a more important finding for the world today.
Hat tip: The still excellent Kevin Lewis.
That is from Infovores.