Gambling Can Save Science
Nearly thirty years ago my GMU colleague Robin Hanson asked, Could Gambling Save Science? We now know that the answer is yes. Robin’s idea to gauge the quality of scientific theories using prediction markets, what he called idea futures, has been validated. Camerer et al. (2018), the latest paper from the Social Science Replication Project, tried to replicate 21 social-science studies published in Nature or Science between 2010 and 2015. Before the replications were run the authors run a prediction market–as they had done on previous replication research–and once again the prediction market did a very good job predicting which studies would replicate and which would not.
Ed Yong summarizes in the Atlantic:
Consider the new results from the Social Sciences Replication Project, in which 24 researchers attempted to replicate social-science studies published between 2010 and 2015 in Nature and Science—the world’s top two scientific journals. The replicators ran much bigger versions of the original studies, recruiting around five times as many volunteers as before. They did all their work in the open, and ran their plans past the teams behind the original experiments. And ultimately, they could only reproduce the results of 13 out of 21 studies—62 percent.
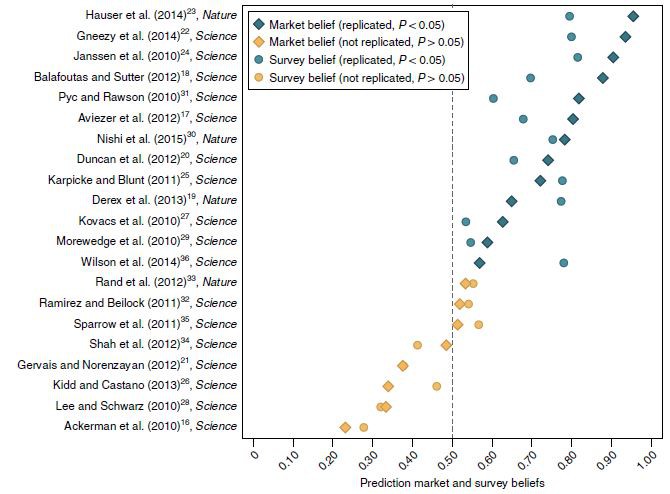
As it turned out, that finding was entirely predictable. While the SSRP team was doing their experimental re-runs, they also ran a “prediction market”—a stock exchange in which volunteers could buy or sell “shares” in the 21 studies, based on how reproducible they seemed. They recruited 206 volunteers—a mix of psychologists and economists, students and professors, none of whom were involved in the SSRP itself. Each started with $100 and could earn more by correctly betting on studies that eventually panned out.
At the start of the market, shares for every study cost $0.50 each. As trading continued, those prices soared and dipped depending on the traders’ activities. And after two weeks, the final price reflected the traders’ collective view on the odds that each study would successfully replicate. So, for example, a stock price of $0.87 would mean a study had an 87 percent chance of replicating. Overall, the traders thought that studies in the market would replicate 63 percent of the time—a figure that was uncannily close to the actual 62-percent success rate.
The traders’ instincts were also unfailingly sound when it came to individual studies. Look at the graph below. The market assigned higher odds of success for the 13 studies that were successfully replicated than the eight that weren’t—compare the blue diamonds to the yellow diamonds.