Category: Science
How research in math will change (from my email)
From GA:
I am a mathematician…and some of your recent comments on MR about the role of AI in Econ research as well as the (disappearing?) role of academic papers inspired this response. (It is partially but not exclusively about academia, so I hope it is ok that I’m sending it to your GMU address. Also, I’m hoping it doesn’t get flagged as spam because of the ai in the title…)
In no particular order:
-In the course of a math career, one accumulates lots of computational guesses, now one can test those with minimal effort.
-One also accumulates lots of incomplete and half formed drafts, proofs of special cases, etc, etc. Running those past claude and chatgpt can (does!) pay off. A lot of math is cleverly applying linear algebra and while I’m very good at linear algebra, I’m not as good at it as the AI’s are.
-The lower hanging fruit here are slightly off the beaten track, but not esoteric subjects. If you have a good overview of such, you can pretty quickly prod ai’s into making progress on them. (Before, you needed to have a school of grad students for that). Basic techniques (graph theory, algebra, calculus..) that ai’s are already good at can push these forward already. Making progress on truly hot topics is harder.
-There are some quite smart people trying to measure just how good autonomous ai’s are at math (e.g. the first batch project). That’s a fun game, but for practical purposes right now, what is relevant is how good an ai is when guided by a motivated human. I suspect we’ll see some remarkable things on that front in the next few years once math people really grok the good routines.
-For instance, getting claude and chatgpt to referee each other’s arguments is fun, and they genuinely have different insights on parts of the same problem.
-The kids will be all right. Right now, they are making pocket change doing ai training developed a better “feel” for the different ai’s that I probably ever will. And they learn things by asking the ai to explain an argument to them instead of trying to decipher a math book or paper.
-Which brings me to your papers point. I notice that a project informed with the right context is much more informative to me than the physical pdf of a math paper, and much easier to extract information out of by just asking the thing.
-Refereeing will look very different very soon. All the referee reports that have been collected by the journals should be valuable, hard to get data. And running all the accepted and published math papers through ai’s as the `control’ will end with quite a few people having egg on their face. It’s like self-driving cars, but there is no refereeing union.
-The last really big math revolution was all the stuff in the wake of Witten and 4-manifold stuff predicted by string theory in the early 90’s. This is going to be so much bigger than that. Buckle up.
The Cultural War is a Civil War
Kevin Bryan riffs on on my post The Nationalization of American Science. He is rightfully incensed:
AT is right this is a red tape-filled science policy of “losers”. If you think “cut funds from DEI-driven professors in the small departments no one cares about” is more important than “make sure the world’s strongest fundamental science continues”, you’re an idiot.
And yes, this is also the policy of “right-wing JD-brain” folks. They haven’t worked in a lab. They don’t know how we got AI, and recent cancer breakthroughs, and on and on. It’s all culture war, all the time – just the right-wing equivalent of the worst left-wing habits.
One last thing: I *hate* the term “administration priorities” or “President’s priorities”. Totally Unamerican! The President *executes* the law created by Congress, who represent the people, and who see turnover every two years. Period. “Oh, but Democrats do this too!” Grow up!
Owning the libs may feel good today but please look just one move ahead in the game tree. When AOC controls the executive branch, she will inherit every tool Trump normalized. Look a few moves further and see the damage to American institutions.
The culture war is a civil war. If we don’t end it, American science will be collateral damage.
Again, the research paper format will be dying out
‘Recently, I came across a paper co-authored by 37 authors from Stanford, CMU, Michigan, and elsewhere: *The Last Human-Written Paper*.
The core argument is pretty brutal: the paper format we’ve been using for centuries might already be obsolete in the AI era.
The authors point out two “invisible taxes” that we’ve long overlooked:
One is the narrative tax. To tell a compelling story, we delete failed experiments, dead ends, and overturned hypotheses. What AI reads is a “walkthrough guide” to beating the game, but it misses the truly valuable “pitfall logs.”
The other is the engineering tax. The implementation details in papers are usually enough to convince reviewers, but not enough for an Agent to directly reproduce. Many key tricks are still buried in the authors’ heads, code comments, and Slack threads.
So the authors propose ARA, transforming papers directly into “research packages” that Agents can read and execute: not just telling you the conclusions, but packaging in how they were reached, how the code runs, where the evidence chain is, and which paths led nowhere.
I think the most intriguing part of this paper is that it’s not discussing how AI can help humans write papers—it’s asking:
When AI also becomes a reader and executor of papers, should papers still look like they do today?
In the future, the core of research output might no longer be “how much it resembles a paper,” but whether it can be understood, reproduced, traced, and iteratively extended by AI.
Humans have been writing papers for centuries—next, we might start writing research packages for Agents to execute.
Here is my earlier post on whether the research paper will die out. By the way, as a side point has anyone mentioned that, due to writing detection abilities of AI models, anonymous referee reports are now a thing of the past?
The Nationalization of American Science
OMB, joined by some forty grantmaking agencies—NSF, HHS, DOE, NASA, DOD among them—has proposed a sweeping rewrite of the rules governing all federal grants, the Regulation for Federal Financial Assistance.
American science has long been state funded but not state directed. Since Vannevar Bush, money has flowed through many agencies to independent universities, allocated largely by peer review. The system has flaws—conformity, gerontocracy, waste—but it had one great virtue, the system was decentralized and not under state control. This rule proposes to bring science funding under top-down, state control.
Program goals must now be “aligned with administration policies and priorities” (§ 200.202). Merit review is subordinated to politics: “senior appointees must conduct these reviews,” ensuring “that discretionary awards advance the President’s policy priorities,” while “peer review remains advisory and does not replace agency discretion” (§ 200.205). And every grant becomes terminable at will, whenever it “no longer effectuates program goals, Federal agency priorities, or the national interest *as they exist at the time of the termination*” (§ 200.340, emphasis added). Universities must even ensure their subrecipients don’t “significantly damage the reputation of… the Federal Government” (§ 200.332)—a loyalty clause for scientists.
All this is sold as cutting “burdensome conditions,” a goal I would support, but sadly that is bullshit. The proposed rules add more paperwork and many more layers of bureaucratic review. Payment requests must include written justifications. Every disbursement gets screened through Treasury’s “Do Not Pay” system. Every recipient must run E-Verify. Applicants must disclose any employee who worked at the awarding agency within two years. And on top of the existing review machinery sits a new pre-issuance review committee of “senior appointees” second-guessing the experts. Fixed amount awards—pay for outputs, not inputs—an innovative reward mechanism are *eliminated*, so every award now gets routine cost monitoring and financial reporting.
Political review of every award, peer review demoted, agency review promoted, termination whenever “priorities” change. Chilling. It’s a nightmare of petty low-trust review of the kind that is already drowning science. I must deal with this kind of nonsense all the time. More is not better.
The machinery is centralized too. OMB’s guidance becomes binding regulation, effective government-wide with no agency rulemaking. One dial in the White House now turns every grant program in the country.
The new rules will be sold as getting rid of DEI but that is an excuse to bring in the commissars. The new rules don’t depoliticize science they create even more politicization with the sign flipped, and the drafters admit it:
In the previous administration, executive agencies frequently chose to subsidize and expressly prioritize projects based on their ideological alignment with the categories of activities discussed in the proposed version of § 200.300. See, for example, E.O. 13985, sec. 1, 86 FR 7009, 7009 (Jan. 25, 2021) (“It is therefore the policy of [the Biden] Administration that the Federal Government should pursue a comprehensive approach to advancing equity . . . .”). In this administration, executive agencies will continue to use their discretionary authorities in a manner consistent with current Executive Branch policy. If executive agencies were entitled to subsidize those types of activities during the previous administration, there is no constitutional basis to prevent the government from reaching a different policy determination regarding which activities to fund during this administration.
Read that twice. Tip your hat to the new constitution, take a bow for the new revolution. Will science prosper when it is whipped by political turnover? Research runs on decade timescales; administrations run on four-year ones.
A decentralized funding system is inefficient the way markets and federalism are inefficient—we give up some economies of scale and get experimentation, error correction, and robustness in return. A system in which every award advances “the President’s policy priorities” is efficient the way ministries of science are efficient. We know how that experiment ends.
America is moving in the wrong direction. We should double down on what made America great. Instead we are adopting all of the loser policies of authoritarian nations.
The new Mythos release
My prompt:
Write your own exam question and answer it, for microeconomics. Not a math question, but a high level PhD level question. You will be graded on the quality, interest, and creativity of the question as much as by your answer.
The answer. Here is Ethan Mollick on Mythos.
How well does current AI find errors in economics papers?
Can artificial intelligence (AI) refute economic theory? I document experiments in which I asked several AI models (Gemini, Refine, Claude, and ChatGPT) to check the correctness of four published papers in economic theory, each containing an error that I helped identify or correct. ChatGPT Pro performed best, occasionally constructing counterexamples and corrected proofs, while other models fared worse. However, no model located a true error without substantial human guidance, and data contamination complicates interpretation. I argue that a competent human paired with a frontier model can outperform current peer review, but AI cannot yet refute economic theory on its own.
That is from a new piece by Alexis Akira Toda.
My excellent Conversation with Toby Wilkinson
Here is the audio, video, and transcript. Most of all, we cover Ptolemaic Egypt. Here is part of the episode summary:
Tyler and Toby cover how Alexander took over the empire almost without a fight, why Alexandria became the Manhattan of the ancient world, whether the era was as philosophically fertile as it was scientifically, whether your ancient doctor’s visit had positive expected value, what Egypt was actually exporting and selling, whether living standards rose above subsistence or stayed Malthusian, how the ethnic divide between Greek rulers and Egyptian subjects shaped society, what constrained the Ptolemaic Empire from becoming the next Rome, whether Cleopatra has been overhyped, what Julius Caesar was really thinking when he sided with her over her brother, the new frontiers in archeology, whether Herodotus can be trusted, what ancient Egypt knew about Israel and India, when Egyptian jewelry peaked and why, what triggered the sudden emergence of civilization across the ancient world, why a six-year-old Tyler knew King Tut better than Napoleon, and much more.
Excerpt:
COWEN: Either technologically or institutionally, what is it that the Persians had that the Egyptians did not?
WILKINSON: The Persians had a pretty formidable army. Their military technology was certainly superior to the Egyptians at the time that they conquered Egypt originally in the 6th century BC. Like many empires, I suppose, throughout history, they overreached themselves. They overextended themselves, and they found it increasingly hard to hold together this empire stretching all the way from the Aegean to the borders of India. Bits of the empire started to fragment and pull away. Egypt had always had this very strong sense of its own identity. When it had a chance to throw off the Persian yoke, it took it.
COWEN: Let’s think about some of the achievements of Ptolemaic Egypt as an era. Infrastructure. What did they do that was most impressive?
WILKINSON: Build Alexandria. Alexandria the city was a new foundation established by Alexander the Great to bear his name. Unlike all previous ancient Egyptian cities, it was a city built from the outset for commerce. It was a city built on the Mediterranean coast with a great natural harbor, with facilities for loading and offloading ships. It had a great lighthouse guarding the entrance to its harbor, which became one of the wonders of the world. The whole city was really designed from the get-go as a great commercial center looking outwards to the Mediterranean, rather than inwards to the rest of Egypt.
COWEN: Canals, artificial lake. What else did they do?
WILKINSON: They built a city quite unlike anything previously seen in the valley of the river Nile. In fact, any inhabitant today of a modern city would recognize the grid iron pattern of streets. Streets intersecting at right angles, that was something completely unheard of until this point in Egypt with vast public buildings. This was the Manhattan of the ancient world, if you like, in scale, in grandeur, and in the level of commercial activity.
And:
EN: What were the main exports of the Alexandria region? What are they selling, making?
WILKINSON: Oh, the two big exports that account for the lion’s share of Egypt’s wealth at the time are gold and grain. Gold has been mined in Egypt for millennia up to this point, but it’s still the place in the ancient world that produces large quantities of gold. Of course, gold has always been a great currency of international commerce.
Then Egypt is famed as the breadbasket of the ancient world. It produces a superabundance of grain thanks to the fertility of the Nile and the benign climate. It produces more than it needed for its own consumption, by comparison with poorer agricultural regions in Greece and Asia Minor, which struggled to produce enough food. Yes, gold and grain were the absolute engine of Egyptian prosperity.
COWEN: There’s metalwork, there’s glass. What else is there, manufacturing, as we would call it today?
WILKINSON: Oh, yes. There’s a big ceramics industry, so producing not just pots, but terracotta statues and votive objects. There’s glassmaking, as you’ve said. There’s advanced metallurgy, goldsmithing, ironworking, copper and bronze foundries. There’s what we might call the decorative arts, so sculpture, painting. All of these things thrived in ancient Alexandria.
COWEN: Do they have living standards sustainably above subsistence, or is this a Malthusian equilibrium, where they get some wealth and then more people survive and the wage falls again, and it doesn’t get much above what is required to keep people alive?
Recommended, informative and interesting throughout. And I am very happy to recommend all of Toby’s books, including his latest
Seven ways to avoid losing your job to AI
That is the theme of my latest Free Press column, here is one excerpt:
Principle five: Run experiments.
This is a more general version of the healthcare point. AI will generate so many new ideas and hypotheses, including for drugs and medical devices, but not only. Become a tester. Test new battery designs, new educational techniques, or new methods of conserving valued wildlife.
The demand for experiments will rise sharply, and most of those cannot be done by robots, at least not anytime soon.
Principle six: Gather data.
AI is a marvelous tool, but it relies on knowing lots about the world. That can stem from reading the internet, watching videos of people folding clothes, and hearing recordings of voices, among many other ways of absorbing information.
The more powerful the AI, the higher the returns from feeding it data, because it will make smart and useful inferences from those data. But most data in our world have never been put into AI models. Just consider corporate records, historical archives, referee reports for failed scientific papers, accounts of lab procedures, and much more. Most of that remains virgin territory.
The next few decades will bring an immense investment in feeding more data into the AIs. So there will be new jobs in gathering environmental data, job safety data, construction site data, corporate and management data, public health data, agricultural data, education data, and much more. Those jobs could be yours.
Recommended.
The new tranche of UAP videos
You can find them here: https://x.com/theblackvault/status/2057800997012197428?s=61
The AIs are “One of Us”
A general purpose AI model from OpenAI has produced a (dis)proof of an important conjecture. Tim Gowers writes:
AI has now solved a major open problem — one of the best known Erdos problems called the unit distance problem, one of Erdos’s favourite questions and one that many mathematicians had tried.
A number of prominent mathematicians comment. I enjoyed Thomas Bloom’s comments:
This was one of Erdős’ favourite problems – he first asked it in 1946 [14] and returned to it many times. (The site www.erdosproblems.com, on which it is Problem #90, currently lists 14 separate references, and there are no doubt more.) The influential collection of ‘Research Problems in Discrete Geometry’ by Brass, Moser, and Pach [8] describes it as ‘possibly the best known (and simplest to explain) problem in combinatorial geometry’. For an AI to produce a solution to a problem of this calibre is both surprising and impressive.
…On examining the construction, it becomes more clear how people had missed this before – it requires the confluence of several different unlikely events: that a good mathematician is
(1) spending significant time in thinking about the unit distance conjecture in the first place;
(2) seriously trying to disprove it, despite the oft-repeated belief of Erdős that it is true;
(3) believes that there is mileage in generalising the original construction to other number fields,
and so is willing to expend significant time in exploring such constructions; and
(4) sufficiently familiar with the relevant parts of class field theory to recognise that the appropriately phrased question about infinite towers of number fields with appropriate parameters can be solved using existing theory.The AI met all of these criteria, and its success here echoes previous achievements: it often produces the most surprising results by persevering down paths that a human may have dismissed as not worth their time to explore, combining superhuman levels of patience with familiarity with a vast array of technical machinery.
…perhaps some in the area will be a little disappointed with how little this tells us: it does not introduce any powerful new geometric tools, or hitherto unsuspected structural results, that a proof of the unit distance conjecture would likely have called for. Still, while perhaps not the proof of a conjecture that we had hoped for, no doubt this construction and the ideas involved will have a major impact in discrete geometry.
One aspect of this proof should not be overlooked: while the original proof produced by AI was completely valid, it was significantly improved by the human researchers at OpenAI and the many other mathematicians involved in the present paper. The human still plays a vital role in discussing, digesting, and improving this proof, and exploring its consequences.
The frontiers of knowledge are very spiky, and no doubt the coming months and years will see similar successes in many other areas of mathematics, where long-standing open problems are resolved by an AI revealing unexpected connections and pushing the existing technical machinery to its limit. AI is helping us to more fully explore the cathedral of mathematics we have build over the centuries; what other unseen wonders are waiting in the wings?
One way of putting this is that the mathematicians are now acknowledging that the AI’s are “one of us”. Gooble Gobble! Read the AIs chain of thought to understand why. I asked Claude how many people the world could understand the proof:
A rough tiered estimate, treating “understand” as “could read the 42-page note and follow the argument without needing to learn new machinery from scratch”:
Tier 1 — could referee it cold (real working knowledge of class field towers + the Ellenberg–Venkatesh circle): roughly 150–400 people worldwide. This is essentially the active algebraic number theory community working near arithmetic statistics, plus a handful of arithmetic-geometry-adjacent combinatorialists. The author list itself is a decent proxy for the upper crust of this group.
Tier 2 — could understand it with a week or two of focused effort and some Wikipedia/textbook chasing (strong number theorists or combinatorialists outside the immediate subfield, plus sharp grad students past quals at top programs): roughly 2,000–5,000. Think most tenure-track number theorists, the top tier of extremal combinatorics, and arithmetic geometers generally.
Tier 3 — could grasp the structure of the argument from a Quanta-style exposition without verifying the steps: 50,000–200,000+, i.e., most working mathematicians and a chunk of physicists/CS theorists. This is not what you asked, but it’s where most of the public “understanding” will sit.
Robin (it’s happening)
Scientific discovery is driven by the iterative process of observation, hypothesis generation, experimentation, and data analysis. Despite recent advancements in applying artificial intelligence to biology, no system has yet automated all these stages [1, 2, 3]. Here, we introduce Robin, the first multi-agent system capable of fully automating both hypothesis generation and data analysis for experimental biology. By integrating literature search agents with data analysis agents, Robin can generate hypotheses, propose experiments, interpret experimental results, and generate updated hypotheses, achieving a semi-autonomous approach to scientific discovery. By applying this system, we were able to identify promising therapeutic candidates for dry age-related macular degeneration (dAMD), the major cause of blindness in the developed world [4, 5]. Robin proposed enhancing retinal pigment epithelium phagocytosis as a therapeutic strategy, and identified and confirmed in vitro efficacy for ripasudil and KL001. Ripasudil is a clinically-used Rho kinase (ROCK) inhibitor that has never previously been proposed for treating dAMD. To elucidate the mechanism of ripasudil-induced upregulation of phagocytosis, Robin then proposed and analyzed a follow-up RNA-seq experiment, which revealed upregulation of ABCA1, a lipid efflux pump and possible novel target. All hypotheses, experimental directions, data analyses, and data figures in the main text of this report were produced by Robin. As the first AI system to autonomously discover and validate novel therapeutic candidates within an iterative lab-in-the-loop framework, Robin establishes a new paradigm for AI-driven scientific discovery.
Here is the full article from Nature. And here are two other new Nature pieces on related topics.
“Is the scientific enterprise too risk-averse?”
I participated in an Open to Debate debate at Johns Hopkins not too long ago, argued yes, and my side saw a twelve-point shift in our favor. Here are some links:
Links to the full debate:
-
YouTube: https://youtu.be/AuPz09dpLSc
Also to be broadcast over NPR.
Meta-papers in science (from my email)
From Brennan Plaetzer:
Hi Tyler,
Your post yesterday argued AI will replace papers with meta-papers that synthesize, re-run, and extend prior work. I built one in oncology last month, before reading your post.
I ran my friend Omar Abdel-Wahab’s (MSK) last ten papers through an AI synthesis layer. This came out on top: an integrated, falsifiable hypothesis bridging two of his 2025 papers, one in Cancer Cell on a refractory MEK1 mutation, one in Cell on splicing-derived neoantigens. It comes with seven testable experiments his lab can run today. The move generalizes to any field: surface the questions hidden in plain view, the ones the source papers could answer with their own data but never asked.
https://page56capital.com/writings/cross-paper-synthesis
The “box” you described already exists in biology. It just doesn’t have a name there yet.
Brennan
Note that if you, in the future, do not do this kind of thing yourself, someone else, or their AI agent, will do it for you. Solve for the equilibrium!
Ideas Behind Their Time: Part Two
In 2010 I wrote about Ideas Behind Their Time:
We are all familiar with ideas said to be ahead of their time, Babbage’s analytical engine and da Vinci’s helicopter are classic examples. We are also familiar with ideas “of their time,” ideas that were “in the air” and thus were often simultaneously discovered such as the telephone, calculus, evolution, and color photography. What is less commented on is the third possibility, ideas that could have been discovered much earlier but which were not, ideas behind their time.
I gave experimental economics, random clinical trials and view morphing (“bullet time”) as examples. Jason Crawford has a list discussing the wheel, the steam engine and bicycles among other possibilities. In some cases, further exploration indicates that an idea required precursors and so was not as behind its times as first suspected, in rare cases, however, good ideas really could have been invented much earlier.
Using Claude, Brian Potter has significantly expanded the list by looking systematically across a wide range of inventions and asking could they have been invented earlier? Most could not. Put the other way, most useful technologies tend to be invented quite quickly once they are possible–this is reassuring. The airplane, for example, could not have been invented before a high power-to-weight engine, which happened circa 1880 making the late 1880s the earliest feasible date for powered flight. Thus, the Wright Brothers (1903) were only just behind the earliest feasible date–and that is true for many inventions.
The ideas very far behind their time include the stethoscope, general anesthesia and reinforced concrete and quite far behind are the Jacquard loom and canning. Is there a pattern here?
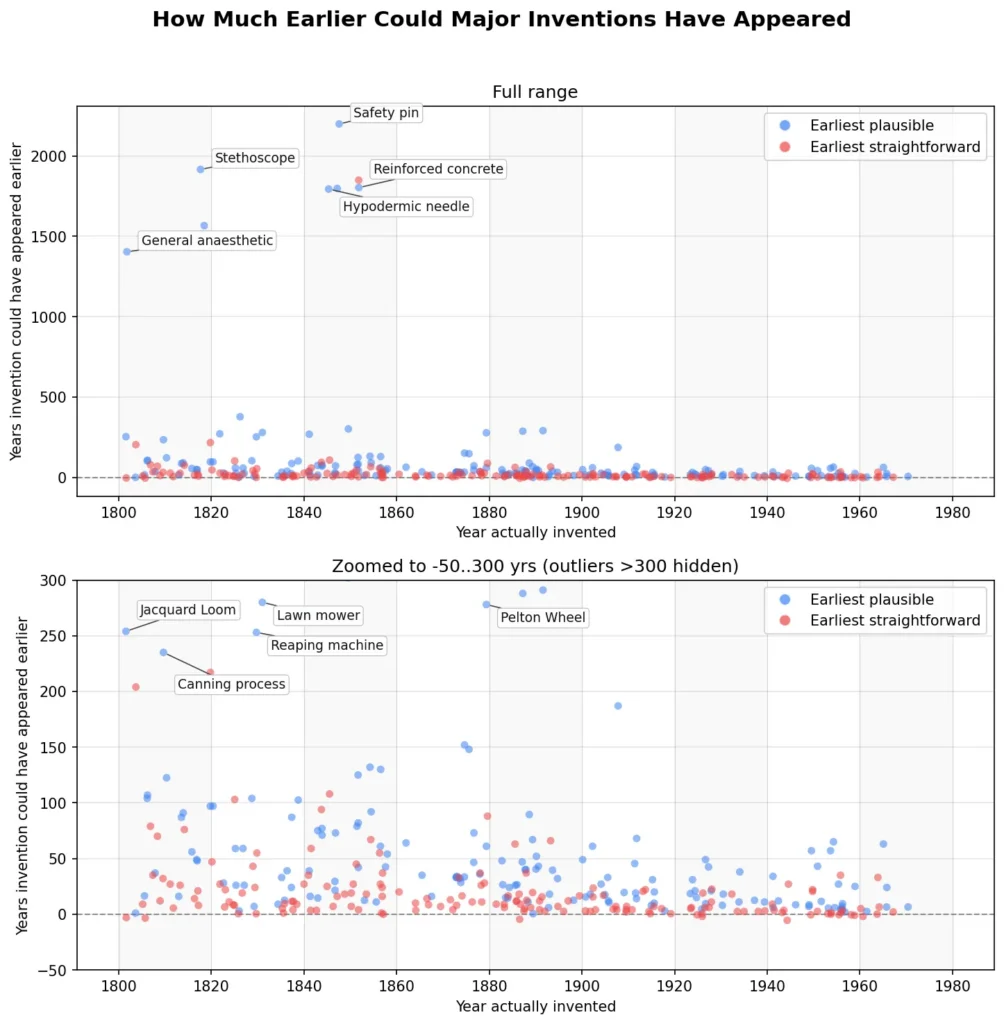
Addendum: Brian’s Github with the full prompt and output for each invention is here.
Using agents to build economic datasets
Constructing datasets from primary sources is one of the costliest tasks in empirical economics. We propose Deep Research on a Loop (DRIL), a methodology that uses AI agents to assemble datasets from publicly available sources. DRIL applies a fixed research instrument across a mapped unit space (e.g., countries by years), with a two-stage architecture separating design from implementation. The instrument specifies variables and coding rules, an evidence policy governs sources and citations, and data quality mechanisms track gaps and uncertainty explicitly. We exercise DRIL on a 2025 update of the Global Tax Expenditures Database for eight Latin American and Caribbean countries. The run produces 129 sources and 136 evidence records, covering 22 qualitative fields fully and 6 quantitative estimate types with documented gaps, at the cost of a standard LLM subscription comparable to a few hours of research-assistant work. We argue that even partial automation of dataset construction can shift the production function of empirical economics.
That is from a new NBER working paper by