Results for “model this” 3659 found
A Model of Populism as a Conspiracy Theory
We model populism as the dissemination of a false “alternative reality,” according to which the intellectual elite conspires against the populist for purely ideological reasons. If enough voters are receptive to it, this alternative reality—by discrediting the elite’s truthful message—reduces political accountability. Elite criticism, because it is more consistent with the alternative reality, strengthens receptive voters’ support for the populist. Alternative realities are endogenously conspiratorial to resist evidence better. Populists, to leverage or strengthen beliefs in the alternative reality, enact harmful policies that may disproportionately harm the non-elite. These results explain previously unexplained facts about populism.
That is from the latest AER, by Adam Szeidl and Ferenc Szucs. In other words, a lot of you are falling for it.
Singapore’s Pay Model Isn’t India’s: Market Wages vs. Civil-Service Rents
In my post How High Government Pay Wastes Talent and Drains Productivity I pointed to evidence that high government compensation in poorer countries creates tremendous waste and drains the private sector of productive talent. A reader asked: What about Singapore?—famous for paying its top officials very well.
Singapore, however, is hardly comparable to India. Its GDP per capita is about 37 times India’s (~$91k vs. $2.4k) and its population is ~1/233rd the size (6m vs. 1.4b). Still, lets take a closer look. 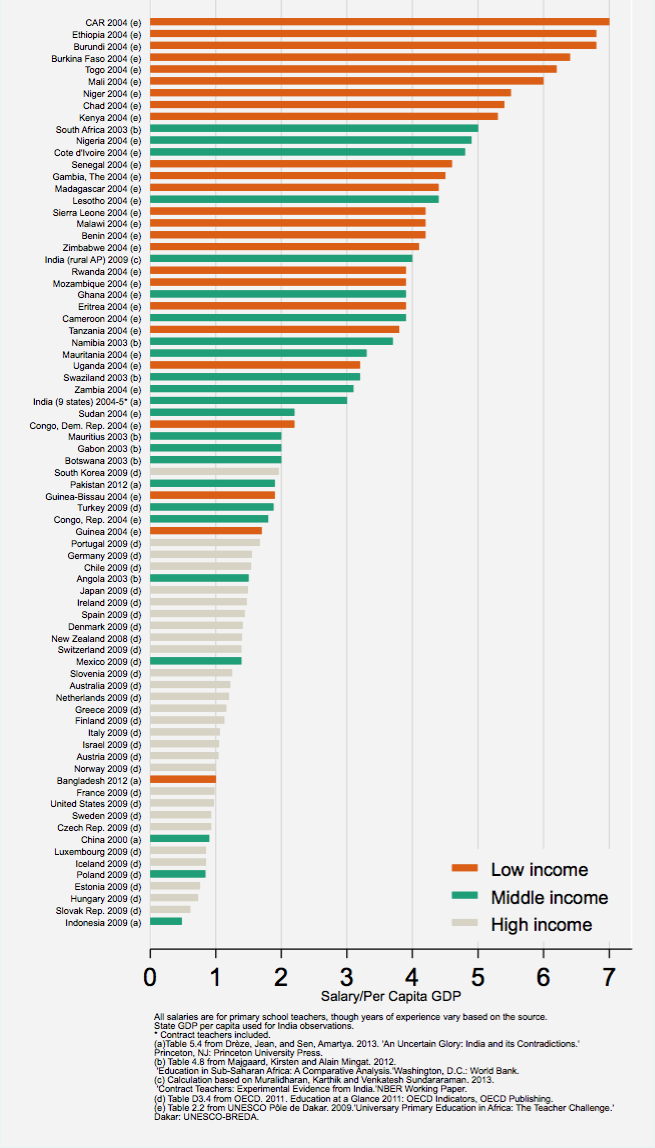
When I discuss high public pay in places like India, Greece, or Brazil, I don’t mean a few top ministers. I mean millions of railway clerks, office staff, and civil servants. Teachers illustrate the point well, since their work is broadly similar worldwide. As Justin Sandefur shows in the data at right, teacher salaries relative to GDP per capita tend to be highest in the poorest countries—sometimes five times GDP per capita or more.
Sandefur comments:
This may come as a bit of a surprise to many rich-country readers. There’s no doubt that teachers in, say, India earn much less than teachers in Ireland, but relative to context, they tend to be very well paid. Dividing by per capita GDP is a rough and ready way to put salaries in context.
The evidence suggests supply and demand can’t explain this. For example, in countries where teachers are highly paid relative to GDP per capita, they’re also paid far above private-sector wages for the same job. Sandefur presents more evidence on this question and concludes:
…Public school teachers in many developing countries earn civil service salaries that are far higher than market wages. This is what economists traditionally refer to as “rents.”
Singapore does NOT fit this pattern. Its teachers earn on the order of 70–80% of GDP per capita, market wages, not inflated packages. What’s unusual in Singapore is only at the top: a small number (fewer than 500) of elite officials and politicians have salaries pegged to the highest 1,000 Singapore-citizen income earners.
The issue Singapore is tackling is wage compression. In many democracies, collective bargaining combined with fairness, envy and inequality concerns pushes pay up at the bottom and down at the top. Denmark and heavily unionized firms are classic cases. Singapore, meritocratic and unapologetic, instead says its highest-ranking officials should be paid like CEOs.
Unlike India, Italy, Greece or Brazil, Singapore’s policy is not to pay any government workers above market wages but to pay competitive salaries to its entire civil service, even those at the top. Crucially, Singapore does not use mass exams to limit entry–it doesn’t have to because by keeping wages consistent with similar jobs in the private sector it matches supply to demand. As a result, we do not see in Singapore thousands or even millions of over-qualified people applying for a handful of over-paid government jobs, as in this example from Italy (quoted in Geromichalos and Kospentaris):
Italy’s chronic unemployment problem has been thrown into sharp relief after 85,000 people applied for 30 jobs at a bank [. . . ] The work is not glamorous – one duty is feeding cash into machines that can distinguish banknotes that are counterfeit or so worn out that they should no longer be in circulation. The Bank of Italy whittled down the applicants to a “shortlist” of 8,000, all of them first-class graduates with a solid academic record behind them. They will have to sit a gruelling examination in which they will be tested on statistics, mathematics, economics and English [. . . ] The high level of interest was a reflection of the state of the economy but also of the Italian obsession with securing “un posto fisso” – a permanent job.
So far from being a counter-example, Singapore illustrates the lesson: Singapore pays market wages, not rents—thereby avoiding the rent-seeking and talent misallocation that plague countries where civil servants are paid far above their market value.
Modeling errors in AI doom circles
There is a new and excellent post by titotal, here is one excerpt:
The AI 2027 have picked one very narrow slice of the possibility space, and have built up their model based on that. There’s nothing wrong with doing that, as long as you’re very clear that’s what you’re doing. But if you want other people to take you seriously, you need to have the evidence to back up that your narrow slice is the right one. And while they do try and argue for it, I think they have failed, and not managed to prove anything at all.
And:
So, to summarise a few of the problems:
For method 1:
- The AI2027 authors assigned a ~40% probability to a specific “superexponential” curve which is guaranteed to shoot to infinity in a couple of years,even if your current time horizon is in the nanoseconds.
- The report provides very few conceptual arguments in favour of the superexponential curve, one of which they don’t endorse and another of which actually argues against their hypothesis.
- The other ~40% or so probability is given to an “exponential” curve, but this is actually superexponential as well due to the additional “intermediate speedups”.
- Their model for “intermediate speedups”, if backcasted, does not match with their own estimates for current day AI speedups.
- Their median exponential curve parameters do not match with the curve in the METR report and match only loosely with historical data. Their median superexponential curve, once speedups are factored in, has an even worse match with historical data.
- A simple curve with three parameters matches just as well with the historical data, but gives drastically different predictions for future time horizons.
- The AI2027 authors have been presenting a “superexponential” curve to the public that appears to be different to the curve they actually use in their modelling.
There is much more detail (and additional scenarios) at the link. For years now, I have been pushing the line of “AI doom talk needs traditional peer review and formal modeling,” and I view this episode as vindication of that view.
Addendum: Here is a not very good non-response from (some of) the authors.
The Return of the American Model
In talking about Operation Warp Speed I repeatedly placed it in the context of what I call the American Model of emergency response. The American model is the fusion of federal spending power with the speed, ingenuity, and innovation of the private sector. It aligns the visible hand of government with the invisible hand of the market. Operation Warp Speed was the most recent example, but the most important demonstration of the American Model was the shift to a wartime economy during World War II.
As Arthur Herman recounts in the excellent Freedom’s Forge, it wasn’t centralized command or sweeping nationalization that turned the United States into the “arsenal of democracy.” It was a partnership between government and business—figures like William Knudsen and Henry Kaiser mobilized private firms to outproduce the Axis through decentralized execution and rapid innovation funded by federal investment and aided by deregulation and the ending of New Deal attacks on markets and entrepreneurs. William Knudsen, the penniless Danish immigrant who worked his way to key positions in Ford and General Motors, being commissioned as a lieutenant general in the United States Army epitomizes the American Model.
In an incredible piece, Shyam Sankar the CTO of Palantir explains why he has accepted a commission as a lieutenant colonel in the Army Reserve’s newly formed Detachment 201: Executive Innovation Corps.
I decided to join the military for reasons both patriotic but also intensely personal.
My father grew up in a mud hut in Tamil Nadu, the southernmost state in India. He was the youngest of nine children and the first in his family to attend college—an education made possible only by his eight siblings pooling their wages. After graduation, he moved to Lagos, Nigeria, to build and run a pharmaceutical plant. Through ingenuity and an enterprising spirit, he became successful at a remarkably young age.
When I was 2, our life in Lagos ended violently. Five armed men broke into our home, killed our dog, pistol-whipped my father, and threatened my mother as they demanded money from the company safe. We fled Lagos with nothing, and started over in America.
My father took a job at a company that supplied souvenirs to theme parks in Orlando, Florida. My childhood memories are punctuated by Space Shuttle launches seen from my school courtyard, and by the bone-rattling double sonic booms of the Shuttles’ reentry. Lessons about the power of American technology were literally falling from the sky around me.
My father never again saw the material success of his youth, and he faced setback after setback in America. But he always reminded me of the counterfactual: “But for the grace of this nation, you would be dead in a ditch in Lagos.” America gave him life, liberty, and possibility.
Many lessons here about immigration, markets, universities, elites and more. Read the whole thing.
New data on the political slant of AI models
By Sean J. Westwood, Justin Grimmer, and Andrew B. Hall:
We develop a new approach that puts users in the role of evaluator, using ecologically valid prompts on 30 political topics and paired comparisons of outputs from 24 LLMs. With 180,126 assessments from 10,007 U.S. respondents, we find that nearly all models are perceived as significantly left-leaning—even by many Democrats—and that one widely used model leans left on 24 of 30 topics. Moreover, we show that when models are prompted to take a neutral stance, they offer more ambivalence, and users perceive the output as more neutral. In turn, Republican users report modestly increased interest in using the models in the future. Because the topics we study tend to focus on value-laden tradeoffs that cannot be resolved with facts, and because we find that members of both parties and independents see evidence of slant across many topics, we do not believe our results reflect a dynamic in which users perceive objective, factual information as having a political slant; nonetheless, we caution that measuring perceptions of political slant is only one among a variety of criteria policymakers and companies may wish to use to evaluate the political content of LLMs. To this end, our framework generalizes across users, topics, and model types, allowing future research to examine many other politically relevant outcomes.
Here is a relevant dashboard with results.
Large Language Models, Small Labor Market Effects
That is a new paper from Denmark, by Anders Humlum and Emilie Vestergaard, here is the abstract:
We examine the labor market effects of AI chatbots using two large-scale adoption surveys (late 2023 and 2024) covering 11 exposed occupations (25,000 workers, 7,000 workplaces), linked to matched employer-employee data in Denmark. AI chatbots are now widespread—most employers encourage their use, many deploy in-house models, and training initiatives are common. These firm-led investments boost adoption, narrow demographic gaps in take-up, enhance workplace utility, and create new job tasks. Yet, despite substantial investments, economic impacts remain minimal. Using difference-in-differences and employer policies as quasi-experimental variation, we estimate precise zeros: AI chatbots have had no significant impact on earnings or recorded hours in any occupation, with confidence intervals ruling out effects larger than 1%. Modest productivity gains (average time savings of 2.8%), combined with weak wage pass-through, help explain these limited labor market effects. Our findings challenge narratives of imminent labor market transformation due to Generative AI.
Not a surprise to me of course. Arjun Ramani offers some interpretations. And elsewhere (FT): “Google’s core search and advertising business grew almost 10 per cent to $50.7bn in the quarter, surpassing estimates for between 8 per cent and 9 per cent.”
Slow takeoff, people, slow takeoff. I hope you are convinced by now.
Naming AI models correctly
Are you confused by all the model names and terminology running around? Here is a simple guide to what I call them:
o1 pro — The Boss
4o — Little Boss
o3 mini — The Mini Boss
GPT 4o with scheduled tasks — Boss come back later
o1 — Cheapskates’ boss
Deep Research — My research assistant
GPT-4 — Former Boss
DeepSeek — China Boss
Claude — Claude
Llama 3.3, or whichever — Meta. I never quite got used to calling Facebook “Meta,” so I call the AI model Meta too. Hope that’s OK!
Grok 3 — Elon
Gemini 2.0 Flash — China Boss suggests “Laggy Larry,” but I don’t actually call it that.
Perplexity.ai — Google
Got that? Easy as pie!
The new o3 model from OpenAI
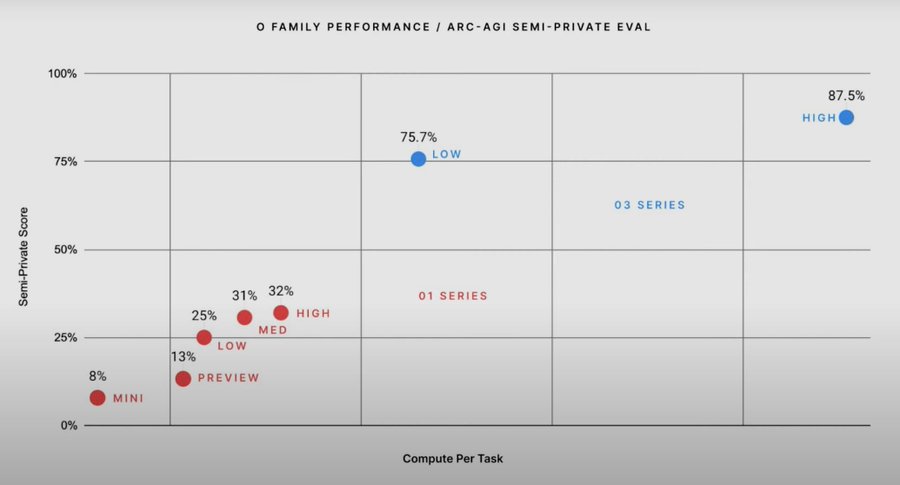
Some more results. And this:
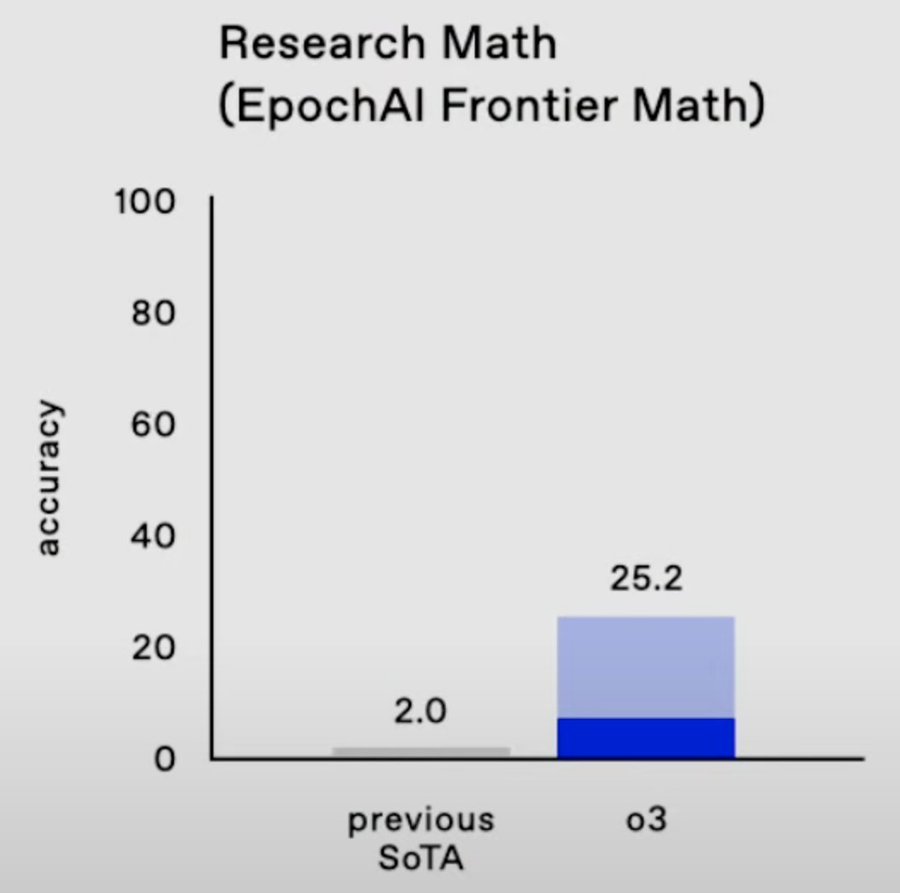
Yupsie-dupsie, delivery of this:

Happy holidays people, hope you are enjoying the presents!
Does the O-Ring model hold for AIs?
Let’s say you have a production process, and the AIs involved operate at IQ = 160, and the humans operate at IQ = 120. The O-Ring model, as you may know, predicts you end up with a productivity akin to IQ = 120. The model, in short, says a production process is no better than its weakest link.
More concretely, it could be the case that the superior insights of the smarter AIs are lost on the people they need to work with. Or overall reliability is lowered by the humans in the production chain. This latter problem is especially important when there is complementarity in the production function, namely that each part has to work well for the whole to work. Many safety problems have that structure.
The overall productivity may end up at a somewhat higher level than IQ = 120, if only because the AIs will work long hours very cheaply. Still, the quality of the final product may be closer to IQ = 120 than you might have wished.
This is another reason why I think AI productivity will spread in the world only slowly.
Sometimes when I read AI commentators I feel they are imagining production processes of AIs only. Eventually, but I do not see that state of affairs as coming anytime soon, if only for legal and regulatory reasons.
Furthermore, those AIs might have some other shortcomings, IQ aside. And an O-Ring logic could apply to those qualities as well, even within the circle of AIs themselves. So if say Claude and the o1 model “work together,” you might end up with the worst of both worlds rather than the best.
The dominance of large factor models in finance
This is less news to the private sector traders on the frontier, but the idea now has reached academia and the NBER working paper series:
We introduce artificial intelligence pricing theory (AIPT). In contrast with the APT’s foundational assumption of a low dimensional factor structure in returns, the AIPT conjectures that returns are driven by a large number of factors. We first verify this conjecture empirically and show that nonlinear models with an exorbitant number of factors (many more than the number of training observations or base assets) are far more successful in describing the out-of-sample behavior of asset returns than simpler standard models. We then theoretically characterize the behavior of large factor pricing models, from which we show that the AIPT’s “many factors” conjecture faithfully explains our empirical findings, while the APT’s “few factors” conjecture is contradicted by the data.
That is from a new paper by
Finally, exchange rate models seem to work pretty well
Exchange-rate models fit very well for the U.S. dollar in the 21st century. A “standard” model that includes real interest rates and a measure of expected inflation for the U.S. and the foreign country, the U.S. comprehensive trade balance, and measures of global risk and liquidity demand is well-supported in the data for the U.S. against other G10 currencies. The monetary and non-monetary variables play equally important roles in explaining exchange rate movements. In the 1970s – early 1990s, the fit of the model was poor but the fit (as measured by t- and F-statistics, and R-squareds) has increased almost monotonically to the present day. We make the case that it is better monetary policy (inflation targeting) that has led to the improvement, as the scope for self-fulfilling expectations has disappeared. We provide a variety of evidence that links changes in monetary policy to the performance of the exchange-rate model.
That is from a new NBER working paper by Charles Engel and Steve P.Y. Wu. For how long will this last?
An overly simple model of positive and negative contagion
When people feel bad and act badly, if only in rhetoric, they make others around them worse as well. That is a simple account of negative contagion of mood.
There is positive contagion too, but it is harder to pull off. If nine people tell you nice things, and one person serves up a somewhat credible insult, it is the insult that sticks with you.
Most social times are a relatively stable mix of positive and negative feelings, but sometimes the dynamics of negative contagion take over, and negativism leads to yet more negativism. Arguably this happened in Europe before WWI, and arguably it is happening in many countries today, including the United States. Very bad events, such as financial crises, also can trigger cycles of negative contagion.
This negative contagion is self-validating. If all the negative feelings, expressed collectively, in fact make outcomes worse, it will seem those negative feelings are justified. In this equilibrium the negative feelings about “opposing others” will be true, but still it would be better to avoid that equilibrium altogether.
A country can get out of a negative cycle either by winning a major war, or when a political entrepreneur comes along with enough oomph and reforms to shift the equilibrium, as Ronald Reagan did in America. Still, negative cycles are hard to break once you get into them. That said, over time things do start to become worse, so options for the positivity entrepreneurs do arise, at least if they can overcome coordination problems and get enough people to feel better.
Many thinkers and writers contribute to this equilibrium of negative feelings, most of all by writing about each other. Even if their substantive points are correct, their social marginal product usually is negative, though you can learn from them because they are competing to offer the most incisive critique.
If you can avoid being overwhelmed by the peer pressure of this negative dynamic, the private and social returns are high. You can just keep on going and build things. Yet few are able to resist the logic of Durkheim, no matter how ostensibly contrarian they may be. In fact the contrarians are often at greatest risk of being caught up in this, because they are so skilled in rejecting and also criticizing the claims of the opposing forces.
Happy Fourth of July!
Financial Statement Analysis with Large Language Models
We investigate whether an LLM can successfully perform financial statement analysis in a way similar to a professional human analyst. We provide standardized and anonymous financial statements to GPT4 and instruct the model to analyze them to determine the direction of future earnings. Even without any narrative or industry-specific information, the LLM outperforms financial analysts in its ability to predict earnings changes. The LLM exhibits a relative advantage over human analysts in situations when the analysts tend to struggle. Furthermore, we find that the prediction accuracy of the LLM is on par with the performance of a narrowly trained state-of-the-art ML model. LLM prediction does not stem from its training memory. Instead, we find that the LLM generates useful narrative insights about a company’s future performance. Lastly, our trading strategies based on GPT’s predictions yield a higher Sharpe ratio and alphas than strategies based on other models. Taken together, our results suggest that LLMs may take a central role in decision-making.
That is from a new paper by Alex Kim, Maximilian Muhn, and Valeri V. Nikolaev, all at Chicago Booth. Via William Allen.
Experimental Evidence on Large Language Models
This paper investigate the formation of inflation expectations using Large Language Models (LLMs) based on different text data. Employing a new experimental design, I integrate generative AI with economic analysis to explore the impact of different information treatments on LLMs’ responses. Results from six distinct knowledge sources reveal that the type of information accessible to an LLM significantly affects the variance of its generated expectations. LLMs with access to relevant economic documents exhibit lower variance compared to those with irrelevant information. Furthermore, information treatments, particularly the one related to mortgage rates, influence the updating of LLMs’ prior inflation expectations, showing similar findings from human surveys. The findings underscore the importance of providing domain-specific knowledge to LLMs and showcase the potential of AI agents in studying expectation formation and decision-making processes in economics.
That is from a new paper by Ali Zarifhonarvar.