Category: Data Source
Race and economic well-being in the United States
We construct a measure of consumption-equivalent welfare for Black and White Americans, which incorporates life expectancy, consumption, leisure, and inequality. Based on these factors, welfare for Black Americans was 40 percent of that for White Americans in 1984 and 59 percent by 2022. There has been remarkable progress for Black Americans: The level of their consumption-equivalent welfare increased by a factor of 3.5 over the last 38 years when aggregate consumption per person only doubled. Despite this progress, the welfare gap in 2022 remains disconcertingly large at 41 percent, much larger than the 16 percent gap in consumption per person.
That is from a new article by Jean-Félix Brouillette, Charles I. Jones, and Peter J. Klenow, just published in American Economic Journal: Insights.
Enlightenment ideas and the belief in progress leading up to the Industrial Revolution
Using textual analysis of 173,031 works printed in England between 1500 and 1900, we test whether British culture evolved to manifest a heightened belief in progress associated with science and industry. Our analysis yields three main findings. First, there was a separation in the language of science and religion beginning in the 17th century. Second, scientific volumes became more progress-oriented during the Enlightenment. Third, industrial works—especially those at the science-political economy nexus—were more progress-oriented beginning in the 17th century. It was therefore the more pragmatic, industrial works which reflected the cultural values cited as important for Britain’s takeoff.
That is from a paper by Ali Almelhem, Murat Iyigun, Austin Kennedy, and Jared Rubin. Now forthcoming at the QJE.
Some second-order effects of unaffordable housing
This is one of the best, most interesting, and most important papers I have seen of late:
Housing affordability has declined sharply in recent decades, leading many younger generations to give up on homeownership. Using a calibrated life-cycle model matched to U.S. data, we project that the cohort born in the 1990s will reach retirement with a homeownership rate roughly 9.6 percentage points lower than that of their parents’ generation. The model also shows that as households’ perceived probability of attaining homeownership falls, they systematically shift their behavior: they consume more relative to their wealth, reduce work effort, and take on riskier investments. We show empirically that renters with relatively low wealth exhibit the same patterns. These responses compound over the life cycle, producing substantially greater wealth dispersion between those who retain hope of homeownership and those who give up. We propose a targeted subsidy that lifts the largest number of young renters above the “giving-up threshold.” This policy yields welfare gains that are 3.2 times those of a uniform transfer and 10.3 times those of a transfer targeted to the bottom 10% of the wealth distribution, while also increasing homeownership rate, raising work effort, and reducing reliance on the social safety net.
That is from Seung Hyeong Lee of Northwestern and Younggeun Yoo of University of Chicago. Via the excellent Kevin Lewis.
Do (human) readers prefer AI writers?
It seems so, do read through the whole abstract:
The use of copyrighted books for training AI models has led to numerous lawsuits from authors concerned about AI’s ability to generate derivative content. Yet it’s unclear whether these models can generate high quality literary text while emulating authors’ styles/voices. To answer this we conducted a preregistered study comparing MFA-trained expert writers with three frontier AI models: ChatGPT, Claude, and Gemini in writing up to 450 word excerpts emulating 50 awardwinning authors’ (including Nobel laureates, Booker Prize winners, and young emerging National Book Award finalists) diverse styles. In blind pairwise evaluations by 159 representative expert (MFA-trained writers from top U.S. writing programs) and lay readers (recruited via Prolific), AI-generated text from in-context prompting was strongly disfavored by experts for both stylistic fidelity (odds ratio [OR]=0.16, p < 10^-8) and writing quality (OR=0.13, p< 10^-7) but showed mixed results with lay readers. However, fine-tuning ChatGPT on individual author’s complete works completely reversed these findings: experts now favored AI-generated text for stylistic fidelity (OR=8.16, p < 10^-13) and writing quality (OR=1.87, p=0.010), with lay readers showing similar shifts. These effects are robust under cluster-robust inference and generalize across authors and styles in author-level heterogeneity analyses. The fine-tuned outputs were rarely flagged as AI-generated (3% rate versus 97% for incontext prompting) by state-of-the-art AI detectors. Mediation analysis reveals this reversal occurs because fine-tuning eliminates detectable AI stylistic quirks (e.g., cliché density) that penalize incontext outputs, altering the relationship between AI detectability and reader preference. While we do not account for additional costs of human effort required to transform raw AI output into cohesive, publishable novel length prose, the median fine-tuning and inference cost of $81 per author represents a dramatic 99.7% reduction compared to typical professional writer compensation. Author-specific fine-tuning thus enables non-verbatim AI writing that readers prefer to expert human writing, thereby providing empirical evidence directly relevant to copyright’s fourth fair-use factor, the “effect upon the potential market or value” of the source works.
That is from a new paper by Tuhin Chakrabarty, Jane C. Ginsburg, and Paramveer Dhillon. For the pointer I thank the excellent Kevin Lewis. I recall an earlier piece showing that LLMs also prefer LLM outputs?
The Effect of Video Watching on Children’s Skills
This paper documents video consumption among school-aged children in the U.S. and explores its impact on human capital development. Video watching is common across all segments of society, yet surprisingly little is known about its developmental consequences. With a bunching identification strategy, we find that an additional hour of daily video consumption has a negative impact on children’s noncognitive skills, with harmful effects on both internalizing behaviors (e.g., depression) and externalizing behaviors (e.g., social difficulties). We find a positive effect on math skills, though the effect on an aggregate measure of cognitive skills is smaller and not statistically significant. These findings are robust and largely stable across most demographics and different ways of measuring skills and video watching. We find evidence that for Hispanic children, video watching has positive effects on both cognitive and noncognitive skills—potentially reflecting its role in supporting cultural assimilation. Interestingly, the marginal effects of video watching remain relatively stable regardless of how much time children spend on the activity, with similar incremental impacts observed among those who watch very little and those who watch for many hours.
That is from a new NBER working paper by
Mexico estimates of the day
Ms Sheinbaum’s government says Mexico’s murder rate has come down by 32% in the year since she took office. Analysis by The Economist confirms that the rate has fallen, though by a significantly smaller margin, 14%. Counting homicides alone misses an important part of the picture, namely the thousands of people who disappear in Mexico every year, many of whom are killed and buried in unmarked graves. A broader view of deadly crime that includes manslaughter, femicide and two-thirds of disappearances (the data for disappearances is imperfect), shows a more modest decline of 6% (see chart). Still, Mexico is on track for about 24,300 murders this year, horribly high, but well below the recent annual average of slightly over 30,000. Ms Sheinbaum is the first Mexican leader in years to push violent crime in the right direction.
Here is more from The Economist.
One-Third of US Families Earn Over $150,000
It’s astonishing that the richest country in world history could convince itself that it was plundered by immigrants and trade. Truly astonishing.
From Jeremy Horpedahl who notes:
This is from the latest Census release of CPS ASEC data, updated through 2024 (see Table F-23 at this link).
In 1967, only 5 percent of US families earned over $150,000 (inflation adjusted).
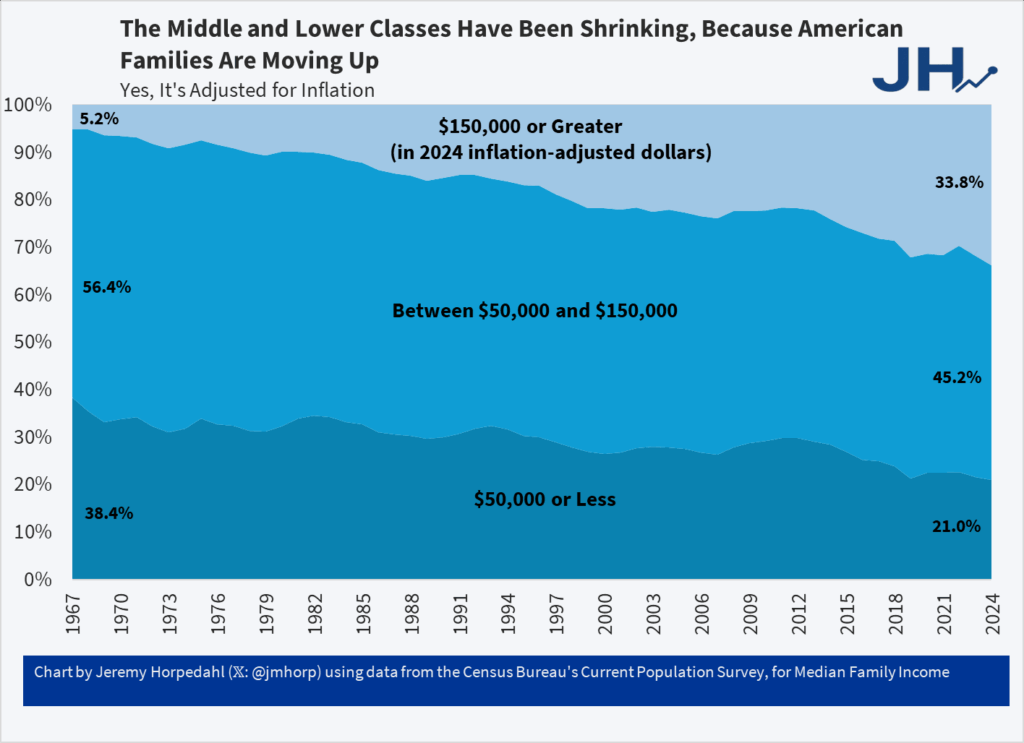
And even though it says so in the chart and in the text let me say it again, this is inflation adjusted and so yes it’s real and no the fact that housing has gone up in price doesn’t negate this, it’s built in. We would have done even better had NIMBYs not reduced the supply of housing.
See also Asness and Strain.
Addendum: Note it isn’t the rise of dual-earner households which haven’t increased for over 30 years.
Old school workplace feminization
We investigate whether consequential decisions made by judges are impacted by the gender composition of these judges’ peer group. Using the universe of decisions on juvenile defendants in each courthouse in a Southern state over 15 years, we estimate two-way fixed effects models leveraging random assignment of cases to judges and variations in judge peer composition generated by judicial turnover. The results show that an increase in the proportion of female peers in the courthouse causes a rise in individual judges’ propensity to incarcerate, and an increase in prison time. This effect is driven by the behavior of female judges. We examine the sensitivity of our findings to heterogeneous-robust difference-in-differences estimators for continuous and nonabsorbing treatments.
Here is the full article by Ozkan Eren and Naci Mocan, tekl.
*Marked by Time*
The author is Robert J, Sampson, and the subtitle is How Social Change has Transformed Crime and the Life Trajectories of Young Americans, from Harvard University Press. Excerpt:
…[for part of Chicago]..the chance of being arrested in life among people born in the mid-1980s is more than double that of those born just a decade later, in the mid-1990s. This large arrest inequality does not arise from early-life individual, family, or local neighborhood characteristics. It arises from the larger and highly divergent socio-historical contexts in which the children grew through adolescence into adulthood.
The particular story focuses on guns, death, and lead exposure, though I wonder whether the in-sample implied elasticities are validated out of sample. Nonetheless an interesting book.
Educational for-profit charter schools do worse in Sweden
I estimate the long-run earnings impacts of for-profit and non-profit charter high schools in Sweden. Since the 1990s, privately managed schools have expanded dramatically—driven entirely by for-profit providers—and now enroll nearly half of urban high school students. Unlike in many other settings, there are no schools operating outside of the public system: all schools rely on equal public funding, cannot charge top-up fees, and are subject to the same regulation. Using a combination of value-added and regression discontinuity methods, I find that charter school attendance reduces long-run earnings by 2% on average—comparable to the returns to half a year of schooling in similar settings. For-profits generate these losses by hiring less-educated, lower-paid teachers, consistent with concerns around cost-cutting. By contrast, non-profits reduce earnings by specializing in arts programs: conditional on such specialization, they perform as or even better than public schools. In a discrete choice framework using rank-ordered school applications, I show that students’ preferences are weakly related to schools’ earnings impacts. Most of the for-profit market share is explained by student demand for attractive locations and study programs, presenting a trade-off between satisfying short-run demand and boosting long-run economic outcomes.
That is the job market paper from Petter Berg, from Stockholm School of Economics.
Supply is elastic, in a new and different setting
The longstanding debate over whether human capabilities and skills are shaped more by “nature” or “nurture” has been revitalized by recent advances in genetics, particularly in the use of polygenic scores (PGSs) to proxy for genetic endowments. Yet, we argue that PGSs embed not only direct genetic effects but also indirect environmental influences, raising questions about their validity for causal analysis. We show that these conflated measures can mislead studies of gene–environment interactions, especially when parental behavior responds to children’s genetic risk. To address this issue, we construct a new latent measure of genetic risk that integrates individual genotypes with diagnostic symptoms, using data from the National Longitudinal Study of Adolescent to Adult Health linked to restricted individual SNP-level genotypes from dbGaP. Exploiting multiple sources of variation—including the Mendelian within-family genetic randomization among siblings—we find consistent evidence that parents compensate by investing more in children with higher genetic risk for ADHD. Strikingly, these compensatory responses disappear when genetic risk is proxied by the conventional ADHD PGS, which also yields weaker—and in some cases reversed—predictions for long-run outcomes. Finally, we embed our latent measure of genetic endowments into a standard dynamic structural model of child development. The model shows that both parental investments and latent genetic risk jointly shape children’s cognitive and mental health development, underscoring the importance of modeling the dynamic interplay between genes and environments in the formation of human capital.
That is from a new NBER working paper, by
Sentences to ponder
We find that interventions (e.g., busing) that move children to a more favorable neighborhood have large effects but lose impact when they are scaled up because parents’ equilibrium responses push against successful integration with the new peer group.
That is from . Here is the NBER version, here is the JPE version.
“Gender without Children”
What would the lives of women look like if they knew from an early age that they would not have children? Would they make different choices about human capital or early career investments? Would they behave differently in the marriage market? Would they fare better in the labor market? In this paper, we follow 152 women diagnosed with the Mayer-Rokitanski-Kuster-Hauser (MRKH) type I syndrome. This congenital condition, diagnosed at puberty, is characterised by the absence of the uterus in otherwise phenotypically normal 46, XX females. Using granular health registries matched with administrative data from Sweden, we confirm that MRKH is not associated with worse health, nor with differential pre-diagnosis characteristics, and that it has a large negative impact on the probability to ever live with a child. Relative to women from the general population, women with the condition have better educational outcomes, tend to marry and divorce at the same rate, but mate with older men, and hold significantly more progressive beliefs regarding gender roles. The condition has also very large positive effects on earnings and employment. Dynamics reveal that most of this positive effect emerges around the arrival of children in women in the general population, with little difference before. We also find that women with MRKH perform as well as men in the labor market in the long run. Results confirm that “child penalties” on the labor market trajectories of women are large and persistent and that they explain the bulk of the remaining gender gap.
That is from recent work by Tatiana Pazem, with co-authors Camille Landais, Peter Lundberg, Erik Plug & Johan Vikstrom. Tatiana is on the job market from LSE, with her main job market paper being “Pension Reforms and Consumption in Retirement: Evidence from French Transactions and Bank Data.”
Does economics make you more sexist?
We provide direct evidence on explicit and implicit biases against women among students in economics relative to other fields. We conducted a large scale survey among undergraduates in Chile, among both entering first-year students and students in years 2 and above, combining a wide battery of measures to create an index of gender bias. Economics students are more biased than students in other fields. There is some evidence that economics students are more biased already upon entry, before exposure to economics classes. The gap becomes more pronounced among students in years 2 and above, especially for male students.
That is from a newly published paper by Valentina Paredes, M. Daniele Paserman, and Francisco J. Pino.
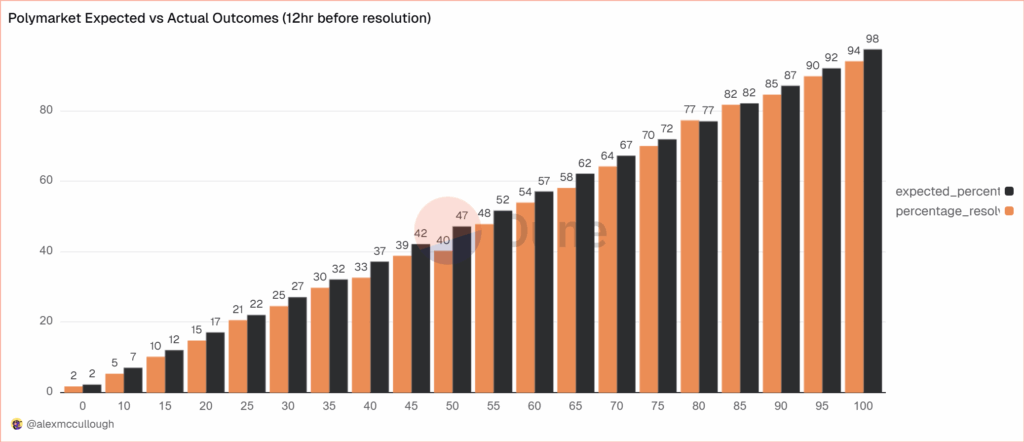
Prediction Markets Are Very Accurate
alexmccullough at Dune has a very good post on the accuracy of Polymarket prediction markets. First, how do we measure accuracy? Suppose a prediction market predicts an event will happen with p=.7, i.e. a 70% probability. The event happens. How do we score this prediction? A common method is the Brier Score which is the mean squared difference from the actual outcome. In this case the Brier Score is (0.70−1)2 = 0.09. Notice that if the prediction market had predicted the event would have happened with 90% probability, a better prediction, then the Brier Score would have been (0.90−1)2 = 0.01 a lower number. If the event had not happened then the Brier Score for a 70% prediction would have been (0.70−0)2 = 0.49, a higher number. Thus, a lower Brier Score is better.
Across some 90,000 predictions the Polymarket Brier Score for a 12 hour ahead prediction is .0581. As Alex notes:
A brier score below 0.125 is good, and below 0.1 is great. Polymarket’s total score is excellent, and puts it on par with the best prediction model’s in existence… Sports betting lines tend to average a brier score of between .18-.22.
Brier Scores have been widely used to measure weather forecasts. A state of the art 12 hour ahead forecast of rain, for example, might have a Brier Score of .0.05 – 0.12 so if Polymarket suggest a metaphorical umbrella you would be wise to listen.
Moreover, highly liquid markets are even more accurate.
Even markets with low liquidity have good brier scores below 0.1, but markets with more than $1m in total trading volume have scores of 0.0256 12 hours prior to resolution and 0.0159 a day prior. It’s hard to overstate how impressive that is.
There are, however, some small but systematic errors. The following bar chart splits events into 20 buckets of 5% each so the first bucket covers events that were predicted to happen 0-5% of the time and the last bucket covers events that were predicted to happen 95-100% of the time. The black bar gives the predicted probability, the orange bar the actual frequencies. As expected, events which are predicted to happen more often do happen more often with a very nice progression. Note, however, that the predicted probability is almost always slightly higher than the actual frequency. This means that people are paying a bit too much. It’s unclear whether this is due to market design issues such as the greater difficult of shorting or something about the Automated Market Makers or due to psychological factors such as favorite bias. Thus, some room for improvement but very impressive overall.