Category: Web/Tech
India AI Data MCP
The Government of India’s Ministry of Statistics and Program Implementation has created an impressive Model Context Protocol (MCP) to connect AI’s to Indian datasets. An AI connected to data via an MCP essentially knows the entire codebook and can make use of the data like an expert. Once connected one can query the data in natural language and quickly create graphs and statistical analysis. I connected Claude to the MCP and created an elegant dashboard with data from India’s Annual Survey of Industries. Check it out.
The mainstream view
Multiple studies have either shown that smartphone and social media use among teens has minimal effects on their mental health or none at all. As a 2024 review published by an American Psychological Association journal put it: “There is no evidence that time spent on social media is correlated with adolescent mental health problems.”
And this:
Advocates of bans compare social media to alcohol or tobacco, where the harms are indisputable and the benefits are minimal. But the internet, including social media, is more analogous to books, magazines or television. I may not want my sons watching “The Texas Chain Saw Massacre” or reading “Fifty Shades of Grey,” but it would be crazy to ban books and films for kids altogether.
But that is the nature of these social media bans. Australia’s law not only restricted access to platforms such as Instagram and TikTok but also banned kids under 16 from having YouTube, X and Reddit accounts. Even Substack had to modify its practices.
Here is more from the excellent Sam Bowman. And many teens make money through “digital side hustles,” in this day and age that is what a teenage job often means.
Liberal AI
Can AI be liberal? In what sense? One answer points to the liberal insistence on freedom of choice, understood as a product of the commitment to personal autonomy and individual dignity. Mill and Hayek are of course defining figures here, emphasizing the epistemic foundations for freedom of choice. “Choice Engines,” powered by AI and authorized or required by law, might promote liberal goals (and in the process, produce significant increases in human welfare). A key reason is that they can simultaneously (1) preserve autonomy, (2) respect dignity, and (3) help people to overcome inadequate information and behavioral biases, which can produce internalities, understood as costs that people impose on their future selves, and also externalities, understood as costs that people impose on others. Different consumers care about different things, of course, which is a reason to insist on a high degree of freedom of choice, even in the presence of internalities and externalities. AI-powered Choice Engines can respect that freedom, not least through personalization. Nonetheless, AI-powered Choice Engines might be enlisted by insufficiently informed or self-interested actors, who might exploit inadequate information or behavioral biases, and thus co5mpromise liberal goals. AI-powered Choice Engines might also be deceptive or manipulative, again compromising liberal goals, and legal safeguards are necessary to reduce the relevant risks. Illiberal or antiliberal AI is not merely imaginable; it is in place. Still, liberal AI is not an oxymoron. It could make life less nasty, less brutish, less short, and less hard – and more free.
The Journal for AI Generated Papers
Science should be machine-readable
One of the leading tasks of our time:
We develop a machine-automated approach for extracting results from papers, which we assess via a comprehensive review of the entire eLife corpus. Our method facilitates a direct comparison of machine and peer review, and sheds light on key challenges that must be overcome in order to facilitate AI-assisted science. In particular, the results point the way towards a machine-readable framework for disseminating scientific information. We therefore argue that publication systems should optimize separately for the dissemination of data and results versus the conveying of novel ideas, and the former should be machine-readable.
Here is the paper by A. Sina Booeshagh, Laura Luebbert, and Lior Pachter. Via John Tierney.
Rebuilding our world, with reference to strong AI
When 2012 passed into 2013, we did not have to rebuild our world, not in most countries at least. It sufficed to make adjustments at the margin.
After the Roman Empire fell, parts of Europe had to rebuild their worlds. It took a long time, but they ended up doing pretty well.
After the American Revolution, the newly independent colonies had to rebuild their own world. They did so brutally, but with considerable success.
After WWII, Western Europe had the chance to rebuild its own world, and did a great job.
We moderns are not used to having to rebuild our world.
It is now the case that strong AI is here/coming, and we will have to rebuild our own world. Many of us are terrified at this prospect, others are just extremely pessimistic. It seems so impossible. How are all the new pieces supposed to fit together? Who amongst us can explain that process in a reassuring way?
Yet we have done it many times before. Not always with success, however. After WWI ended, Europe was supposed to rebuild its own world, but they came up with something far worse than what they had before. Nonetheless, in the broader sweep of history world rebuilding projects have had positive expected value.
And so we will rebuilding our world yet again. Or maybe you think we are simply incapable of that.
As this happens, it can be useful to distinguish “criticisms of AI” from “people who cannot imagine that world rebuilding will go well.” A lot of what parades as the former is actually the latter.
In any case, it all will be quite something to witness.
India’s AI wedding buffet
Shruti Rajagopalan surveys much of the AI policy debate in India. Excerpt:
If there is a single domain where India’s AI ambitions will succeed or fail, it is energy. And energy in India is not a technology problem. It is a political economy problem, arguably the most intractable one the country faces.
India’s peak electricity demand hit 250 GW in May 2024, up from 143 GW a decade earlier. The IEA forecasts 6.3 percent annual growth through 2027, faster than any major economy. Cooling demand alone could reach 140 GW of peak load by 2030. One number captures the trajectory. For each incremental degree in daily average temperature, peak demand now rises by more than 7 GW. In 2019 the figure was half that. India is getting hotter, richer, and more electricity-hungry simultaneously.
State-controlled distribution companies have accumulated $83.7 billion in debt because energy prices have been politically distorted for decades. Over 50 GW of renewable capacity sits underutilized. About 60 GW is stranded behind inadequate transmission. The shortage is financial and infrastructural, not resource-based. Without reforming distribution pricing, governance, and grid investment ($50 billion estimated by 2035), new renewable capacity will not become reliable electricity. It will become another line item on a DISCOM balance sheet no one wants to read.
India’s electricity reaches consumers through 72 distribution companies, 44 of them state-owned, collectively the most financially distressed utilities in the world. Accumulated losses stood at ₹6.92 trillion ($76.89 billion) as of March 2024, rising every year despite five government bailouts since 2002.
Substantive throughout.
Natural and Artificial Ice
Excellent Veritasium video on the 19th century ice industry. Shipping ice from America to India would hardly seem like a wise idea—it’s hard to imagine ever getting a committee to approve such a venture—but entrepreneurs are free to try wacky ideas all the time, and sometimes they pay off, resulting in great riches. That’s the story of the “Ice King,” Frederic Tudor, who lost money for years before figuring out the insulation and logistics needed to make the trade profitable.
What I hadn’t fully appreciated is how the ice trade reshaped shipping, diet, and city design before the invention of mechanical refrigeration. Ice created the cold chain, and the cold chain made it possible to move fresh meat, fish, and produce over long distances. That in turn enabled cities to grow far beyond what local agriculture could support and shifted the American diet from salted and smoked provisions toward fresh food.
The profits of the ice trade encouraged investment in artificial ice which initially was met with resistance—natural ice is created by God!—a classic example of incumbents wrapping their economic interests in moral language, a pattern we see repeated with every disruptive technology from margarine to ridesharing.
Lots of lessons in the video about option value, permissionless innovation, and creative destruction. New technologies destroy old industries and create new ones that no one could have foreseen. The moral panic over artificial ice replacing the natural kind is no doubt familiar.
Hat tip: Naveen Nvn
Minimum wage hikes and robots
This paper studies how minimum wage policy affects firms’ adoption of automation technologies. Using both state-level measures of robot exposure and novel plant-level data on industrial robot imports linked to U.S. Census microdata from 1992-2021, we show that increases in minimum wages raise the likelihood of robot adoption in manufacturing. Our preferred identification exploits discontinuities at state borders, comparing otherwise similar firms exposed to different wage floors. Across specifications, a 10 percent increase in the minimum wage increases robot adoption by roughly 8 percent relative to the mean.
That is from Erik Brynjolfsson, et.al., including Andrew Wang. Via the excellent Kevin Lewis.
By the way, a photo from our textbook Modern Principles of Economics:

Those new service sector jobs
Who needs to be a programmer, be hired to close the doors on Waymo vehicles:
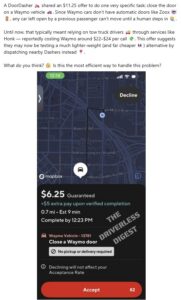
Or see here. And more text from TechCrunch. Via Glenn Mercer, Tom McCarthy, and also Air Genius Gary Leff.
The import of cross-task productivity
Given that LLMs seem to be able to automate so many small tasks, why don’t we see large productivity effects?
I drafted a short paper recently exploring the possibility that it’s for the same reason (or at least one of the reasons) that labor is typically bundled into multi-task jobs, instead of transacted by the task, in the first place: because performing a task increases one’s productivity not only at the task itself but at related tasks.
For example, say you used to spend half your time coding and half your time debugging, and the LLM can automate the coding but you still have to do the debugging. If you’re more productive at debugging code you write yourself, this (1) explains why “coder” and “debugger” aren’t separate jobs, and (2) predicts that the LLM won’t save half your time. If you’re half as productive at debugging code you didn’t write, or less, the LLM saves you no time at all.
So I was excited to see @judyhshen and @alextamkin’s paper from a week or two ago finding basically just that!
At least the way I’m thinking about it, “cross-task learning” should make the productivity impacts of automating tasks more convex: – Automating the second half of a job should be expected to have much more of an impact than automating the first half; and – If the machines can learn from their and each others’ experience, as a worker learns by doing from her own experience, then automating two jobs will have more than twice the impact of automating one.
That is from Philip Trammell. Here is his short piece. Here is the Shen and Tamkin paper. This is all very important work for why the AI growth take-off will be much slower than the power of the models themselves might otherwise indicate. The phrase “…and then all at once” nonetheless applies. But when?
These short pieces and observations are likely among the most important outputs economists will produce this year. But are they being suitably rewarded?
Optimal timing for superintelligence
There is a new paper by Nick Bostrom with that title:
Developing superintelligence is not like playing Russian roulette; it is more like undergoing risky surgery for a condition that will otherwise prove fatal. We examine optimal timing from a person-affecting stance (and set aside simulation hypotheses and other arcane considerations). Models incorporating safety progress, temporal discounting, quality-of-life differentials, and concave QALY utilities suggest that even high catastrophe probabilities are often worth accepting. Prioritarian weighting further shortens timelines. For many parameter settings, the optimal strategy would involve moving quickly to AGI capability, then pausing briefly before full deployment: swift to harbor, slow to berth. But poorly implemented pauses could do more harm than good.
Via Nabeel.
Past Automation and Future A.I.: How Weak Links Tame the Growth Explosion
From Charles I. Jones and Christopher Tonetti:
How muchof past economic growth is due to automation, and what does this imply about the effects of A.I. and automation in the coming decades? We perform growth accounting using a task-based model for key sectors in the U.S. economy. Historically, TFP growth is largely due to improvements in capital productivity. The annual growth rate of capital productivity is at least 5pp larger than the sum of labor and factor-neutral productivity growth. The main benefit of automation is that we use rapidly-improving machines instead of slowly-improving humans on anincreasing set of tasks. Looking to the future, we develop an endogenous growth model in which the production of both goods and ideas is endogenously automated. We calibrate this model based on our historical evidence. Two key findings emerge. First, automation leads economic growth to accelerate over the next 75 years. Second, the acceleration is remarkably slow. By 2040, output is only 4% higher than it would have been without the growth acceleration, and by 2060 the gain is still only 19%. A key reason for the slow acceleration is the prominence of “weak links” (an elasticity of substitution among tasks less than one). Even when most tasks are automated by rapidly improving capital, output is constrained by the tasks performed by slowly-improving labor.
And an important sentence from the paper itself:
…, the key gain from automation is that it allows production of a task to shift away from slowly-improving human labor to rapidly-improving machines.
The authors stress that those are preliminary results, and the numbers are likely to change. For the pointer I thank the excellent Kurtis Hingl, who is also my research assistant.
Recursive self-improvement from AI models
With Claude Opus 4.6 and 5.3 Codex, both stellar achievements, the pace is heating up:
OpenAI went from its last Codex release, on December 18, 2025, to what is widely acknowledged to be a much more powerful one in less than two months. This compares to frequent gaps of six months or even a year between releases. If OpenAI can continue at that rate, that means we can easily get four major updates in a year.
But the results from what people in the AI world call “recursive self-improvement” could be more radical than that. After the next one or two iterations are in place, the model will probably be able to update itself more rapidly yet. Let us say that by the third update within a year, an additional update can occur within a mere month. For the latter part of that year, all of a sudden we could get six updates—one a month: a faster pace yet.
It will depend on the exact numbers you postulate, but it is easy to see that pretty quickly, the pace of improvement might be as much as five to ten times higher with AI doing most of the programming. That is the scenario we are headed for, and it was revealed through last week’s releases.
Various complications bind the pace of improvement. For the foreseeable future, the AIs require human guidance and assistance in improving themselves. That places an upper bound on how fast the improvements can come. A company’s legal department may need to approve any new model release, and a marketing plan has to be drawn up. The final decisions lie in the hands of humans. Data pipelines, product integration, and safety testing present additional delays, and the expenses of energy and compute become increasingly important problems.
And:
Where the advance really matters is for advanced programming tasks. If you wish to build your own app, that is now possible in short order. If a gaming company wants to design and then test a new game concept, that process will go much faster than before. A lot of the work done by major software companies now can be done by much smaller teams, and at lower cost. Improvements in areas such as chip design and drone software will come much more quickly. And those advances filter into areas like making movies, in which the already-rapid advance of AI will be further accelerated.
Here is more from me at The Free Press.
The politics of using AI
Using new data from the Gallup Workforce Panel, we document a persistent partisan gap in self-reported AI use at work: Democrats are consistently more likely than Republicans to report frequent use. In 2025:Q4, for example, 27.8% of Democrats report using AI weekly or daily, compared with 22.5% of Republicans. Democrats also report deeper task-level integration, using AI in 16% more work activities than Republicans. Consistent with this, Democrats are employed in occupations with higher predicted AI exposure based on task-content measures and report larger perceived differences in AI-related job displacement risk. However, in regression models the partisan gap in AI use disappears once we control for education, industry, and occupation, indicating that observed differences primarily reflect compositional variation rather than political affiliation per se.
That is from a new paper by Nicholas Bloom and Christos Makridis.