Category: Science
AI and the Detection of Gravity Waves
Researchers at the Laser Interferometer Gravitational-Wave Observatory, the giant two-observatory machine to detect gravitational waves, developed an AI to improve the sensitivity of the design:
Wired: Initially, the AI’s designs seemed outlandish. “The outputs that the thing was giving us were really not comprehensible by people,” Adhikari said. “They were too complicated, and they looked like alien things or AI things. Just nothing that a human being would make, because it had no sense of symmetry, beauty, anything. It was just a mess.”
The researchers figured out how to clean up the AI’s outputs to produce interpretable ideas. Even so, the researchers were befuddled by the AI’s design. “If my students had tried to give me this thing, I would have said, ‘No, no, that’s ridiculous,’” Adhikari said. But the design was clearly effective.
It took months of effort to understand what the AI was doing. It turned out that the machine had used a counterintuitive trick to achieve its goals. It added an additional three-kilometer-long ring between the main interferometer and the detector to circulate the light before it exited the interferometer’s arms. Adhikari’s team realized that the AI was probably using some esoteric theoretical principles that Russian physicists had identified decades ago to reduce quantum mechanical noise. No one had ever pursued those ideas experimentally. “It takes a lot to think this far outside of the accepted solution,” Adhikari said. “We really needed the AI.”
…If the AI’s insights had been available when LIGO was being built, “we would have had something like 10 or 15 percent better LIGO sensitivity all along,” he said. In a world of sub-proton precision, 10 to 15 percent is enormous.
As with AlphaGO and Move 37 the AI developed entirely novel approaches:
“LIGO is this huge thing that thousands of people have been thinking about deeply for 40 years,” said Aephraim Steinberg, an expert on quantum optics at the University of Toronto. “They’ve thought of everything they could have, and anything new [the AI] comes up with is a demonstration that it’s something thousands of people failed to do.”
Bird trivia
Potvin’s team dissected and examined the bodies of nearly 500 birds belonging to five common Australian species: the Australian magpie, laughing kookaburra, crested pigeon, rainbow lorikeet, and the scaly breasted lorikeet(…)In addition to identifying the birds’ reproductive organs, researchers also tested their DNA to reveal their genetic sex.
The team was surprised to find sex-reversed individuals in all five species, at rates of 3% to 6%. Nearly all these discordant birds were genetically female but had male reproductive organs. However, the researchers also found a few genetic males with ovaries—including a genetically male kookaburra with a distended oviduct, indicating it had recently laid an egg(…)
Here is the full article by Phie Jacobs. Via John.
The Rising Returns to R&D: Ideas Are not Getting Harder to Find (one hypothesis)
R&D investment has grown robustly, yet aggregate productivity growth has stagnated. Is this because “ideas are getting harder to find”? This paper uses micro-data from the US Census Bureau to explore the relationship between R&D and productivity in the manufacturing sector from 1976 to 2018. We find that both the elasticity of output (TFP) with respect to R&D and the marginal returns to R&D have risen sharply. Exploring factors affecting returns, we conclude that R&D obsolescence rates must have risen. Using a novel estimation approach, we find consistent evidence of sharply rising technological rivalry and obsolescence. These findings suggest that R&D has become more effective at finding productivity-enhancing ideas, but these ideas may also render rivals’ technologies obsolete, making innovations more transient. Because of obsolescence, rising R&D does not necessarily mean rising aggregate productivity growth.
Here is the paper by Yoshiki Ando (Singapore Management University, TPRI), James Bessen (BU, TPRI), and Xiupeng Wang. Via Arjun.
New data on tenure
Tenure is a defining feature of the US academic system with significant implications for research productivity and creative search. Yet the impact of tenure on faculty research trajectories remains poorly understood. We analyze the careers of 12,000 US faculty across 15 disciplines to reveal key patterns, pre- and post-tenure. Publication rates rise sharply during the tenure-track, peaking just before tenure. However, post-tenure trajectories diverge: Researchers in lab-based fields sustain high output, while those in non-lab-based fields typically exhibit a decline. After tenure, faculty produce more novel works, though fewer highly cited papers. These findings highlight tenure’s pivotal role in shaping scientific careers, offering insights into the interplay between academic incentives, creativity, and impact while informing debates about the academic system.
Here is the paper. That is by Giorgio Tripodi, Ziang Zheng, Yifan Qian, and Dashun Wang, via the excellent Kevin Lewis.
Genius, Rejected: Emergent Ventures Versus the System
Quanta Magazine has a good piece on a 17-year-old student who disproved a long-standing conjecture in harmonic analysis:
Yet a paper posted on February 10(opens a new tab) left the math world by turns stunned, delighted and ready to welcome a bold new talent into its midst. Its author was Hannah Cairo(opens a new tab), just 17 at the time. She had solved a 40-year-old mystery about how functions behave, called the Mizohata-Takeuchi conjecture.
“We were all shocked, absolutely. I don’t remember ever seeing anything like that,” said Itamar Oliveira (opens aof the University of Birmingham, who has spent the past two years trying to prove that the conjecture was true. In her paper, Cairo showed that it’s false. The result defies mathematicians’ usual intuitions about what functions can and cannot do.
…The proof, and its unlikely author, have energized the math community since Cairo posted it in February. “I was absolutely, ‘Wow.’ This has been my favorite problem for nigh on 40 years, and I was completely blown away,” Carbery said.
Here is the abstract to the paper:

I can’t speak to the mathematics but this is Quanta Magazine not People Magazine and Cairo is not coming out of nowhere. As the article discusses, she has been taking graduate classes in mathematics at Berkeley from people like Ruixiang Zhang. So what is the problem?
I was enraged by the following:
After completing the proof, she decided to apply straight to graduate school, skipping college (and a high school diploma) altogether. As she saw it, she was already living the life of a graduate student. Cairo applied to 10 graduate programs. Six rejected her because she didn’t have a college degree. Two admitted her, but then higher-ups in those universities’ administrations overrode those decisions.
Only the University of Maryland and Johns Hopkins University were willing to welcome her straight into a doctoral program.
Kudos to UMD and JHU! But what is going on at those other universities?!! Their sole mission is to identify and nurture talent. They have armies of admissions staff and tout their “holistic” approach to recognizing creativity and intellectual promise even when it follows an unconventional path. Yet they can’t make room for a genius who has been vetted by some of the top mathematicians in the world? This is institutional failure.
We saw similar failures during COVID: researchers at Yale’s School of Public Health, working on new tests, couldn’t get funding from their own billion-dollar institution and would have stalled without Tyler’s Fast Grants. But the problem isn’t just speed. Emergent Ventures isn’t about speed but about discovering talent. If you wonder why EV has been so successful look to Tyler and people like Shruti Rajagopalan and to the noble funders but look also to the fact that their competitors are so bureaucratic that they can’t recognize talent even when it is thrust upon them.
It’s a very good thing EV exists. But you know your city is broken when you need Batman to fight crime. EV will have truly succeeded when the rest of the system is inspired into raising its game.
Berthold and Emanuel Lasker
A fun rabbit hole! Berthold was world chess champion Emanuel Lasker’s older brother, and also his first wife was Elsa Lasker-Schüler, the avant-garde German Jewish poet and playwright.
In the 1880s (!) he developed what later was called “Fischer Random” chess, Chess960, or now “freestyle chess,” as Magnus Carlsen has dubbed it. The opening arrangement of the pieces is randomized on the back rank, to make the game more interesting and also avoid the risks of excessive opening preparation and too many draws. He was prescient in this regard, though at the time chess was very far from having exhausted the possiblities for interesting openings that were not played out.
For a while he was one of the top ten chess players in the world, and he served as mentor to his brother Emanuel. Emanuel, in due time, became world chess champion, was an avid and excellent bridge and go player, invented a variant of checkers called “Lasca,” made significant contributions to mathematics, and was known for his work in Kantian philosophy.
Of all world chess champions, he is perhaps the one whose peers failed to give him much of a serious challenge. Until of course Capablanca beat him in 1921.
Design Your Own Rug!
For my wedding anniversary, I designed and had hand-woven in Afghanistan a rug for my microbiologist wife. The rug mixes traditional Afghanistan designs with some scientific elements including Bunsen burners, test tubes, bacterial petri dishes and other elements.

I started with several AI designs, such as that shown below, to give the weavers an idea of what I was looking for. Some of the AI elements were muddled and very complex and so we developed a blueprint over a few iterations. The blueprint was very accurate to the actual rug.

I am very pleased with the final product. The wool is of high quality, deep and luxurious, and the design is exactly what I intended. My wife loves the rug and will hang it at her office. The price was very reasonable, under $1000. I also like that I employed weavers in a small village in Northern Afghanistan. The whole process took about 6 months.
You can develop your own custom rug from Afghanu Rugs. Tell them Alex sent you. Of course, they also have many beautiful traditional designs. You can even order my design should you so desire!
That was then, this is now, AI edition
COWEN: They can now do Math Olympiad problems. There’s one forecast by someone working on this that, within a year, they’ll win Math Olympiads. It could be wrong, but when you say that it’s only a year away, I would take that pretty seriously.
That was from my Nate Silver CWT taped on July 22, 2024. We just taped a new episode today…
Noam Brown reports
Today, we at @OpenAI achieved a milestone that many considered years away: gold medal-level performance on the 2025 IMO with a general reasoning LLM—under the same time limits as humans, without tools.
Here is the link, here is some commentary. And Nat McAleese. And the prediction market. Emad: “Two years ago, who would have said an IMO gold medal & topping benchmarks isn’t AGI?” And it is good at other things too.
And from Alexander Wei: “Btw, we are releasing GPT-5 soon, and we’re excited for you to try it. But just to be clear: the IMO gold LLM is an experimental research model. We don’t plan to release anything with this level of math capability for several months.”
David Brooks on the AI race
When it comes to confidence, some nations have it and some don’t. Some nations once had it but then lost it. Last week on his blog, “Marginal Revolution,” Alex Tabarrok, a George Mason economist, asked us to compare America’s behavior during Cold War I (against the Soviet Union) with America’s behavior during Cold War II (against China). I look at that difference and I see a stark contrast — between a nation back in the 1950s that possessed an assumed self-confidence versus a nation today that is even more powerful but has had its easy self-confidence stripped away.
There is much more at the NYT link.
The Sputnik vs. Deep Seek Moment: The Answers
In The Sputnik vs. DeepSeek Moment I pointed out that the US response to Sputnik was fierce competition. Following Sputnik, we increased funding for education, especially math, science and foreign languages, organizations like ARPA were spun up, federal funding for R&D was increased, immigration rules were loosened, foreign talent was attracted and tariff barriers continued to fall. In contrast, the response to what I called the “DeepSeek” moment has been nearly the opposite. Why did Sputnik spark investment while DeepSeek sparks retrenchment? I examine four explanations from the comments and argue that the rise of zero-sum thinking best fits the data.
Several comments fixated on DeepSeek itself, dismissing it as neither impressive nor threatening. Perhaps but DeepSeek was merely a symbol for China’s broader rise: the world’s largest exporter, manufacturer, electricity producer, and military by headcount. These critiques missed the point.
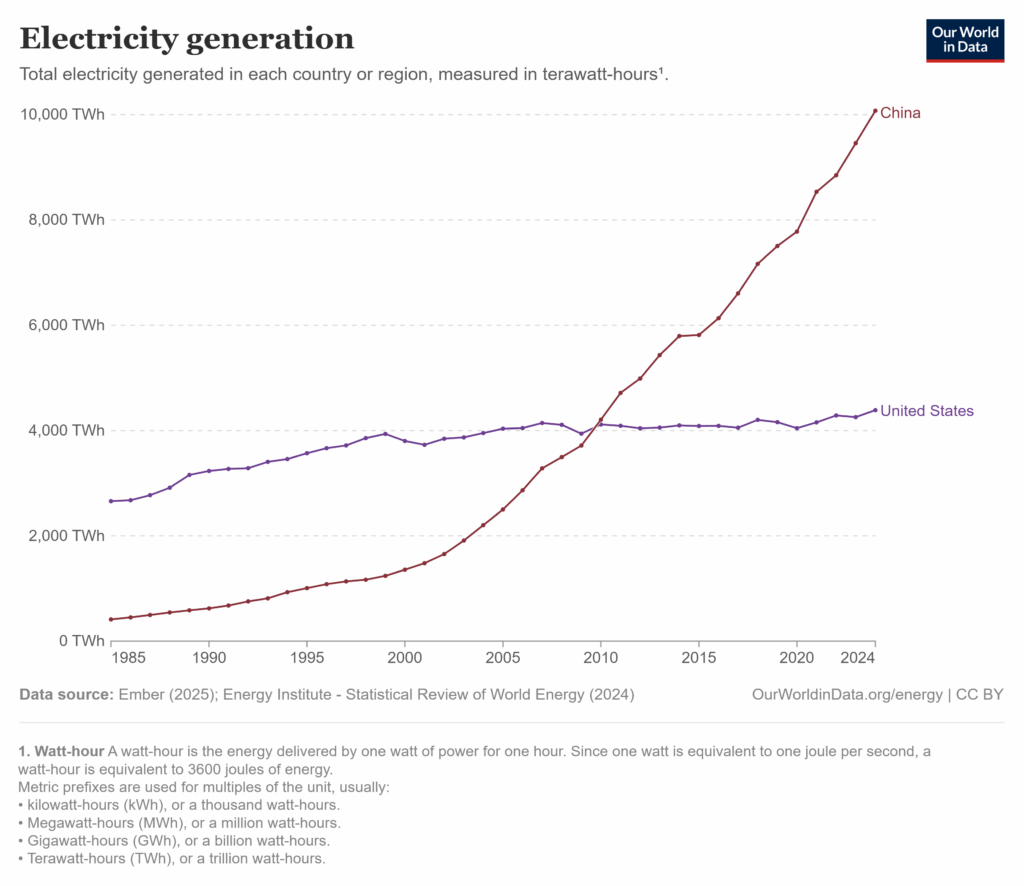
Some commenters argued that Sputnik provoked a strong response because it was seen as an existential threat, while DeepSeek—and by extension China—is not. I certainly hope China’s rise isn’t existential, and I’m encouraged that China lacks the Soviet Union’s revolutionary zeal. As I’ve said, a richer China offers benefits to the United States.
But many influential voices do view China as a very serious, even existential, threat—and unlike the USSR, China is economically formidable.
More to the point, perceived existential stakes don’t answer my question. If the threat were greater, would we suddenly liberalize immigration, expand trade, and fund universities? Unlikely. A more plausible scenario is that if the threat were greater, we would restrict harder—more tariffs, less immigration, more internal conflict.
Several commenters, including my colleague Garett Jones, pointed to demographics—especially voter demographics. The median age has risen from 30 in 1950 to 39 in recent years; today’s older, wealthier, more diverse electorate may be more risk-averse and inward-looking. There’s something to this, but it’s not sufficient. Changes in the X variables haven’t been enough to explain the change in response given constant Betas so demography doesn’t push that far but does it even push in the right direction?
Age might correlate with risk-aversion, for example, but the Trump coalition isn’t risk-averse—it’s angry and disruptive, pushing through bold and often rash policy changes.
A related explanation is that the U.S. state has far less fiscal and political slack today than it did in 1957. As I argued in Launching, we’ve become a warfare–welfare state—possibly at the expense of being an innovation state. Fiscal constraints are real, but the deeper issue is changing preferences. It’s not that we want to return to the moon and can’t—it’s that we’ve stopped wanting to go.
In my view, the best explanation for the starkly different responses to the Sputnik and DeepSeek moments is the rise of zero-sum thinking—the belief that one group’s gain must come at another’s expense. Chinoy, Nunn, Sequiera and Stantcheva show that the zero sum mindset has grown markedly in the U.S. and maps directly onto key policy attitudes.
Zero sum thinking fuels support for trade protection: if other countries gain, we must be losing. It drives opposition to immigration: if immigrants benefit, natives must suffer. And it even helps explain hostility toward universities and the desire to cut science funding. For the zero-sum thinker, there’s no such thing as a public good or even a shared national interest—only “us” versus “them.” In this framework, funding top universities isn’t investing in cancer research; it’s enriching elites at everyone else’s expense. Any claim to broader benefit is seen as a smokescreen for redistributing status, power, and money to “them.”
Zero-sum thinking doesn’t just explain the response to China; it’s also amplified by the China threat. (hence in direct opposition to some of the above theories, the people who most push the idea that the China threat is existential are the ones who are most pushing the zero sum response). Davidai and Tepper summarize:
People often exhibit zero-sum beliefs when they feel threatened, such as when they think that their (or their group’s) resources are at risk…Similarly, working under assertive leaders (versus approachable and likeable leaders) causally increases domain-specific zero-sum beliefs about success….. General zero-sum beliefs are more prevalent among people who see social interactions as a competition and among people who possess personality traits associated with high threat susceptibility, such as low agreeableness and high psychopathy, narcissism and Machiavellianism.
Zero-sum thinking can also explain the anger we see in the United States:
At the intrapersonal level, greater endorsement of general zero-sum beliefs is associated with more negative (and less positive) affect, more greed and lower life satisfaction. In addition, people with general zero-sum beliefs tend to be overly cynical, see society as unjust, distrust their fellow citizens and societal institutions, espouse more populist attitudes, and disengage from potentially beneficial interactions.
…Together, these findings suggest a clear association between both types of zero-sum belief and well-being.
Focusing on zero-sum thinking gives us a different perspective on some of the demographic issues. In the United States, for example, the young are more zero-sum thinkers than the old and immigrants tend to be less zero-sum thinkers than natives. The likeliest reason: those who’ve experienced growth understand that everyone can get a larger slice from a growing pie while those who have experienced stagnation conclude that it’s us or them.
The looming danger is thus the zero-sum trap: the more people believe that wealth, status, and well-being are zero-sum, the more they back policies that make the world zero-sum. Restricting trade, blocking immigration, and slashing science funding don’t grow the pie. Zero-sum thinking leads to zero-sum policies, which produce zero-sum outcomes—making the zero sum worldview a self-fulfilling prophecy.
Someday I want to see the regressions
Each infant born from the procedure carries DNA from a man and two women. It involves transferring the nucleus from the fertilised egg of a woman carrying harmful mitochondrial mutations into a donated egg from which the nucleus has been removed.
For some carriers this is the only option because conventional IVF does not produce enough healthy embryos to use after pre-implantation diagnosis.
The researchers consistently reject the popular term “three-parent babies”, said Turnbull, “but it doesn’t make a scrap of difference.”
Here is more from Clive Cookson at the FT. From Newcastle. And here is some BBC coverage.
A Unifying Framework for Robust and Efficient Inference with Unstructured Data
This paper presents a general framework for conducting efficient inference on parameters derived from unstructured data, which include text, images, audio, and video. Economists have long used unstructured data by first extracting low-dimensional structured features (e.g., the topic or sentiment of a text), since the raw data are too high-dimensional and uninterpretable to include directly in empirical analyses. The rise of deep neural networks has accelerated this practice by greatly reducing the costs of extracting structured data at scale, but neural networks do not make generically unbiased predictions. This potentially propagates bias to the downstream estimators that incorporate imputed structured data, and the availability of different off-the-shelf neural networks with different biases moreover raises p-hacking concerns. To address these challenges, we reframe inference with unstructured data as a problem of missing structured data, where structured variables are imputed from high-dimensional unstructured inputs. This perspective allows us to apply classic results from semiparametric inference, leading to estimators that are valid, efficient, and robust. We formalize this approach with MAR-S, a framework that unifies and extends existing methods for debiased inference using machine learning predictions, connecting them to familiar problems such as causal inference. Within this framework, we develop robust and efficient estimators for both descriptive and causal estimands and address challenges like inference with aggregated and transformed missing structured data-a common scenario that is not covered by existing work. These methods-and the accompanying implementation package-provide economists with accessible tools for constructing unbiased estimators using unstructured data in a wide range of applications, as we demonstrate by re-analyzing several influential studies.
That is from a recent paper by Jacob Carlson and Melissa Dell. Via Kevin Bryan.
*Breakneck: China’s Quest to Engineer the Future*

Trump Administration Launches Probe Into Yale’s Use of Hacked EJMR Data
Christopher Brunet offers his version of the story. While I believe the original research methods were unethical, I very much prefer not to have the federal government involved in this matter.