Category: Medicine
More corruption in the Harvard leadership
Harvard School of Public Health Dean Andrea A. Baccarelli received at least $150,000 to testify against Tylenol’s manufacturer in 2023 — two years before he published research used by the Trump administration to link the drug to autism, a connection experts say is tenuous at best.
Baccarelli served as an expert witness on behalf of parents and guardians of children suing Johnson & Johnson, the manufacturer of Tylenol at the time. U.S. District Court Judge Denise L. Cote dismissed the case last year due to a lack of scientific evidence, throwing out Baccarelli’s testimony in the process.
“He cherry-picked and misrepresented study results and refused to acknowledge the role of genetics in the etiology” of autism spectrum disorder or ADHD, Cote wrote in her decision, which the plaintiffs have since appealed.
Here is more from The Crimson.
AI and the FDA
Dean Ball has an excellent survey of the AI landscape and policy that includes this:
The speed of drug development will increase within a few years, and we will see headlines along the lines of “10 New Computationally Validated Drugs Discovered by One Company This Week,” probably toward the last quarter of the decade. But no American will feel those benefits, because the Food and Drug Administration’s approval backlog will be at record highs. A prominent, Silicon Valley-based pharmaceutical startup will threaten to move to a friendlier jurisdiction such as the United Arab Emirates, and they may in fact do it.
Eventually, I expect the FDA and other regulators to do something to break the logjam. It is likely to perceived as reckless by many, including virtually everyone in the opposite party of whomever holds the White House at the time it happens. What medicines you consume could take on a techno-political valence.
Agreed—but the nearer-term upside is repurposing. Once a drug has been FDA approved for one use, physicians can prescribe it for any use. New uses for old drugs are often discovered, so the off-label market is large. The key advantage of off-label prescribing is speed: a new use can be described in the medical literature and physicians can start applying that knowledge immediately, without the cost and delay of new FDA trials. When the RECOVERY trial provided evidence that an already-approved drug, dexamethasone, was effective against some stages of COVID, for example, physicians started prescribing it within hours. If dexamethasone had had to go through new FDA-efficacy trials a million people would likely have died in the interim. With thousands of already approved drugs there is a significant opportunity for AI to discover new uses for old drugs. Remember, every side-effect is potentially a main effect for a different condition.
On Ball’s main point, I agree: there is considerable room for AI-discovered drugs, and this will strain the current FDA system. The challenge is threefold.
First, as Ball notes, more candidate drugs at lower cost means other regulators may become competitive with the FDA. China is the obvious case: it is now large and wealthy enough to be an independent market, and its regulators have streamlined approvals and improved clinical trials. More new drugs now emerge from China than from Europe.
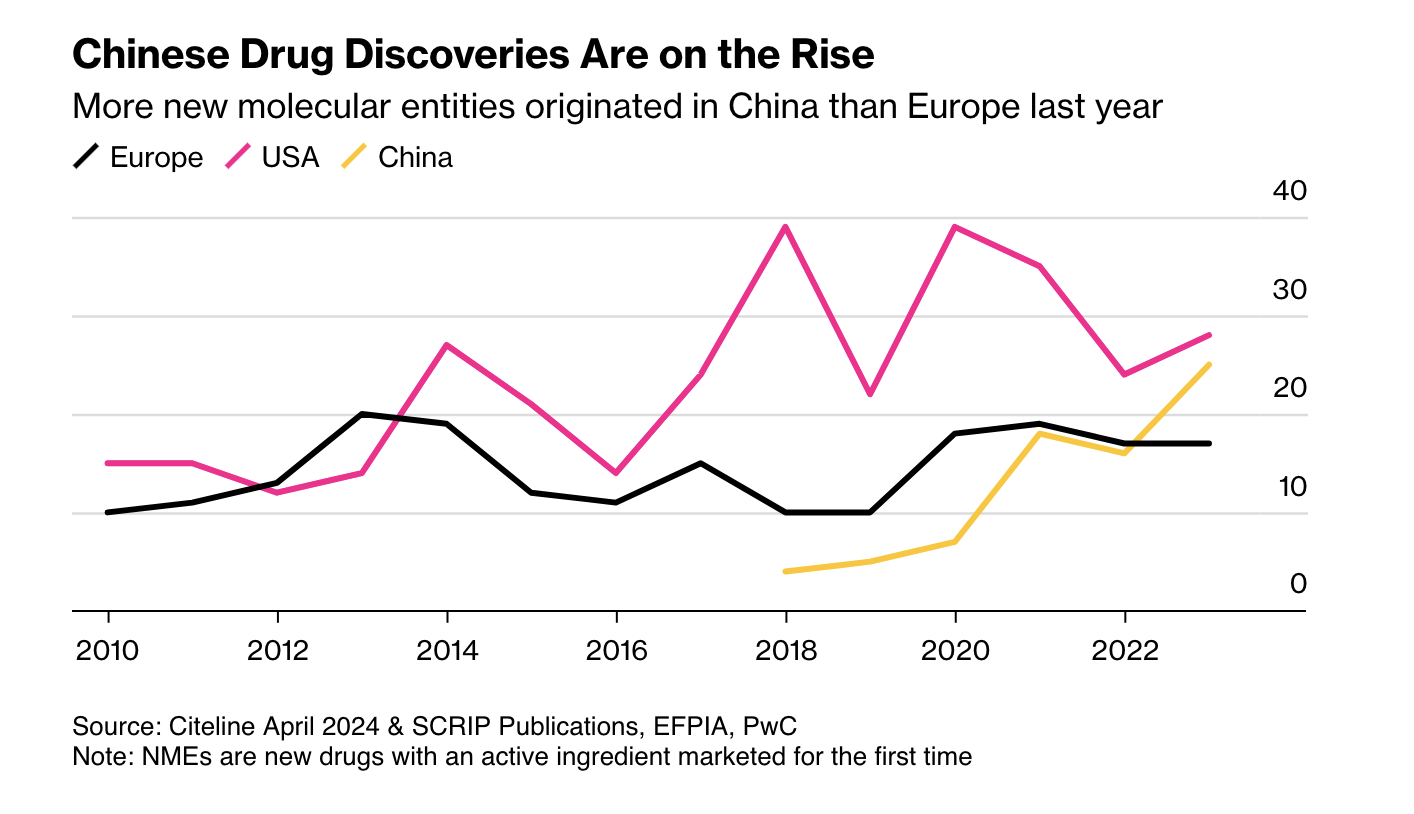
Second, AI pushes us toward rational drug design. RCTs were a major advance, but they are in some sense primitive. Once a mechanic has diagnosed a problem, the mechanic doesn’t run a RCT to determine the solution. The mechanic fixes the problem! As our knowledge of the body grows, medicine should look more like car repair: precise, targeted, and not reliant on averages.
Closely related is the rise of personalized medicine. As I wrote in A New FDA for the Age of Personalized, Molecular Medicine:
Each patient is a unique, dynamic system and at the molecular level diseases are heterogeneous even when symptoms are not. In just the last few years we have expanded breast cancer into first four and now ten different types of cancer and the subdivision is likely to continue as knowledge expands. Match heterogeneous patients against heterogeneous diseases and the result is a high dimension system that cannot be well navigated with expensive, randomized controlled trials. As a result, the FDA ends up throwing out many drugs that could do good.
RCTs tell us about average treatment effects, but the more we treat patients as unique, the less relevant those averages become.
AI holds a lot of promise for more effective, better targeted drugs but the full promise will only be unlocked if the FDA also adapts.
Girls improve student mental health
Using individual-level data from the Add Health surveys, we leverage idiosyncratic variation in gender composition across cohorts within the same school to examine whether being exposed to a higher share of female peers affects mental health and school satisfaction. We find that being exposed to a higher proportion of female peers, despite only improving school satisfaction for boys, improves mental health for both boys and girls. The benefits are greater among boys of low socioeconomic backgrounds, who would otherwise be more likely to be exposed to violent and disruptive peers. We find suggestive evidence that the mechanisms driving our findings are consistent with stronger school friendships for boys and better self-image and grades for girls.
That is from a new NBER working paper by Monica Deza and Maria Zhu.
Is it the phones?

Or perhaps we should just credit Sydney Sweeney? That is from Chris Said.
One look at negative emotional contagion
This paper studies how peers’ genetic predisposition to depression affects own mental health during adolescence and early adulthood using data from the National Longitudinal Study of Adolescent to Adult Health (Add Health). I exploit variation within schools and across grades in same-gender grademates’ average polygenic score—a linear index of genetic variants—for major depressive disorder (the MDD score). An increase in peers’ genetic risk for depression has immediate negative impacts on own mental health. A one standard deviation increase in same-gender grademates’ average MDD score significantly increases the probability of being depressed by 1.9 and 3.8 percentage points for adolescent girls (a 7.2% increase) and boys (a 25% increase), respectively. The effects persist into adulthood for females, but not males. I explore several potential mechanisms underlying the effects and find that an increase in peers’ genetic risk for depression in adolescence worsens friendship, increases substance use, and leads to lower socioeconomic status. These effects are stronger for females than males. Overall, the results suggest that there are important social-genetic effects in the context of mental health.
That is from a recent paper by Yeongmi Jeong, via the excellent Kevin Lewis.
Where are the trillion dollar biotech companies?
In today’s market, even companies with multiple approved drugs can trade below their cash balances. Given this, it is truly perplexing to see AI-biotechs raise mega-rounds at the preclinical stage – Xaira with a billion-dollar seed, Isomorphic with $600M, EvolutionaryScale with $142M, and InceptiveBio with $100M, to name a few. The scale and stage of these rounds reflect some investors’ belief that AI-biology pairing can bend the drug discovery economics I described before.
To me, the question of whether AI will be helpful in drug discovery is not as interesting as the question of whether AI can turn a 2-billion-dollar drug development into a 200-million-dollar drug development, or whether 10 years to approve a drug can become 5 years to approve a drug. AI will be used to assist drug discovery in the same way software has been used for decades, and, given enough time, we know it will change everything [4]. But is “enough time” 3 years or half a century?
One number that is worth appreciating is that 80% of all costs associated with bringing a drug to market come from clinical-stage work. That is, if we ever get to molecules designed and preclinically validated in under 1 year, we’ll be impacting only a small fraction of what makes drug discovery hard. This productivity gain cap is especially striking given that the majority of the data we can use to train models today is still preclinical, and, in most cases, even pre-animal. A perfect model predictive of in vitro tox saves you time on running in vitro tox (which is less than a few weeks anyway!), doesn’t bridge the in vitro to animal translation gap, and especially does not affect the dreaded animal-to-human jump. As such, perfecting predictive validity for preclinical work is the current best-case scenario for the industry. Though we don’t have a sufficient amount and types of data to solve even that.
Here is the full and very interesting essay, from the excellent Lada Nuzhna.
Decker and KingoftheCoast on single payer health insurance
Here is the conclusion of the piece:
To reiterate, the key point in this piece is that high administrative costs in US healthcare are unlikely to represent “do-nothing waste.” Some of the purported costs are entirely fake. To include them in the possible savings of single payer shows either ignorance or dishonesty. Some of the costs are to prevent waste and fraud, which should be paid by Medicare now (although they are not). Of what is left, the cost of duplication pales in comparison to the plausible benefits of choice and competition in health insurance. When you put all of these together, the case for single-payer is nonexistent. A better system would be to subsidize those who are too poor to pay, scrap the government health insurance providers and the VA, remove the employer tax deduction, and allow providers to compete.
Here is the full piece, excellent work.
Do not forget
Estimating real-world vaccine effectiveness is vital to assessing the coronavirus disease 2019 (COVID-19) vaccination program and informing the ongoing policy response. However, estimating vaccine effectiveness using observational data is inherently challenging because of the nonrandomized design and potential for unmeasured confounding. We used a regression discontinuity design to estimate vaccine effectiveness against COVID-19 mortality in England using the fact that people aged 80 years or older were prioritized for the vaccine rollout. The prioritization led to a large discrepancy in vaccination rates among people aged 80–84 years compared with those aged 75–79 at the beginning of the vaccination campaign. We found a corresponding difference in COVID-19 mortality but not in non-COVID-19 mortality, suggesting that our approach appropriately addressed the issue of unmeasured confounding factors. Our results suggest that the first vaccine dose reduced the risk of COVID-19 death by 52.6% (95% confidence limits: 15.7, 73.4) in those aged 80 years, supporting existing evidence that a first dose of a COVID-19 vaccine had a strong protective effect against COVID-19 mortality in older adults. The regression discontinuity model’s estimate of vaccine effectiveness is only slightly lower than those of previously published studies using different methods, suggesting that these estimates are unlikely to be substantially affected by unmeasured confounding factors.
From Charlotte Bermingham, et.al. There is plenty of other research yielding broadly similar conclusions. The Covid vaccines saved millions of lives, well over two million lives even from a conservative estimate.
For the pointer I thank Alex T.
Dean Ball on state-level AI laws
He is now out of government and has resumed writing his Substack. Here is one excerpt from his latest:
Several states have banned (see also “regulated,” “put guardrails on” for the polite phraseology) the use of AI for mental health services. Nevada, for example, passed a law (AB 406) that bans schools from “[using] artificial intelligence to perform the functions and duties of a school counselor, school psychologist, or school social worker,” though it indicates that such human employees are free to use AI in the performance of their work provided that they comply with school policies for the use of AI. Some school districts, no doubt, will end up making policies that effectively ban any AI use at all by those employees. If the law stopped here, I’d be fine with it; not supportive, not hopeful about the likely outcomes, but fine nonetheless.
But the Nevada law, and a similar law passed in Illinois, goes further than that. They also impose regulations on AI developers, stating that it is illegal for them to explicitly or implicitly claim of their models that (quoting from the Nevada law):
(a) The artificial intelligence system is capable of providing professional mental or behavioral health care;
(b) A user of the artificial intelligence system may interact with any feature of the artificial intelligence system which simulates human conversation in order to obtain professional mental or behavioral health care; or
(c) The artificial intelligence system, or any component, feature, avatar or embodiment of the artificial intelligence system is a provider of mental or behavioral health care, a therapist, a clinical therapist, a counselor, a psychiatrist, a doctor or any other term commonly used to refer to a provider of professional mental health or behavioral health care.
First there is the fact that the law uses an extremely broad definition of AI that covers a huge swath of modern software. This means that it may become trickier to market older machine learning-based systems that have been used in the provision of mental healthcare, for instance in the detection psychological stress, dementia, intoxication, epilepsy, intellectual disability, or substance abuse (all conditions explicitly included in Nevada’s statutory definition of mental health).
But there is something deeper here, too. Nevada AB 406, and its similar companion in Illinois, deal with AI in mental healthcare by simply pretending it does not exist. “Sure, AI may be a useful tool for organizing information,” these legislators seem to be saying, “but only a human could ever do mental healthcare.”
And then there are hundreds of thousands, if not millions, of Americans who use chatbots for something that resembles mental healthcare every day. Should those people be using language models in this way? If they cannot afford a therapist, is it better that they talk to a low-cost chatbot, or no one at all? Up to what point of mental distress? What should or could the developers of language models do to ensure that their products do the right thing in mental health-related contexts? What is the right thing to do?
The State of Nevada would prefer not to think about such issues. Instead, they want to deny that they are issues in the first place and instead insist that school employees and occupationally licensed human professionals are the only parties capable of providing mental healthcare services (I wonder what interest groups drove the passage of this law?).
Free the Patient: A Competitive-Federalism Fix for Telemedicine
During the pandemic, many restrictions on telemedicine were lifted, making it far easier for physicians to treat patients across state lines. That window has largely closed. Today, unless a doctor is separately licensed in a patient’s state—or the states have a formal agreement—remote care is often illegal. So if you live in Virginia and want a second opinion from a Mayo Clinic physician in Florida, you may have to fly to Florida, unless that Florida physician happens to hold a Virginia license.
The standard framing says this is a problem of physician licensing. That leads directly to calls for interstate compacts or federalizing medical licensure. Mutual recognition is good. Driver’s licenses are issued by states but are valid in every state. No one complains that Florida’s regime endangers Virginians. But mutual recognition or federal licensing is not the only solution nor the only way to think about this issue.
The real issue isn’t who licenses doctors. It’s that patients are forbidden from choosing a licensed doctor in another state. We can keep state-level licensing, but free the patient. Let any American consult any physician licensed in any state. That’s competitive federalism—no compacts, no federal agency, just patient choice.
A close parallel comes from credit markets. After Marquette Nat. Bank v. First of Omaha (1978), host states could no longer block their residents from using credit cards issued by national banks chartered elsewhere. A Virginian can legally borrow on a South Dakota credit card at South Dakota’s rates. Nothing changed about South Dakota’s licensing; what changed was the prohibition on choice.
Consider Justice Brennan’s argument in this case:
“Minnesota residents were always free to visit Nebraska and receive loans in that state.” It hadn’t been suggested that Minnesota’s laws would apply in that instance, he added. Therefore, they shouldn’t be applied just because “the convenience of modern mail” allowed Minnesotans to get credit without having to visit Nebraska.
Exactly analogously, everyone agrees that Virginia residents are free to visit Florida and be treated by Florida physicians. No one suggests that Virginia’s laws should follow VA residents to Florida. Therefore, VA’s laws shouldn’t be applied just because the convenience of modern online tools allow Virginians to get medical advice and consultation without having to visit Florida.
In short, patients should be allowed to choose physicians as easily as borrowers choose banks.
What to Watch (or Not): Ballard, Perfect Days, Billy Joel
Ballard (Amazon Prime) — I liked Bosch, so I had high hopes for this spinoff. The core premise—a team of misfits solving cold cases—is solid enough but the writing is unimaginative and lazy. In one scene, Ballard is told she needs to get a confession. We expect clever interrogation tactics. Instead, she walks in and bluntly asks, “Did you shoot Yulia Kravetz?”
 Maggie Q is charismatic but the writers don’t write for her. She’s exceptionally slim, for example, yet the show repeatedly asks us to believe she can physically overpower men twice her size. I have no problem with that in a superhero movie but it’s off putting in a show that pretends to be grounded and gritty. If you’re casting someone with that physique, write her as sharper, more cunning, more insightful—not as a female stand-in for macho Bosch.
Maggie Q is charismatic but the writers don’t write for her. She’s exceptionally slim, for example, yet the show repeatedly asks us to believe she can physically overpower men twice her size. I have no problem with that in a superhero movie but it’s off putting in a show that pretends to be grounded and gritty. If you’re casting someone with that physique, write her as sharper, more cunning, more insightful—not as a female stand-in for macho Bosch.
Worst of all is the ending: a killer reveal that comes out of nowhere, with no foreshadowing or internal logic. The writers don’t understand the difference between a twist and a cheat. Disappointing.
Perfect Days (Hulu, Amazon) — a 2023 Wim Wenders film that won the award at Cannes for “works of artistic quality which witnesses to the power of film to reveal the mysterious depths of human beings through what concerns them, their hurts and failings as well as their hopes.” The film follows the life of Hirayama (Kōji Yakusho, who won at Cannes for best actor) as he cleans public toilets in Tokyo’s Shibuya district. You will not be surprised to learn that the movie proceeds slowly. The toilets and the cleaning are the most interesting part of the first hour! I say this not as critique–I liked Perfect Days and the toilets really are interesting–only to illustrate the kind of movie that it is.
It helps to know the following from a useful Sean Burns review:
Komorebi is a Japanese word for the dancing shadow patterns created by sunlight shining through the rustling leaves of trees. There’s no equivalent term in English, and it’s tough to imagine any American caring enough to come up with one. But every afternoon on his lunch break, Hirayama (Koji Yakusho) takes a picture of the komorebi from his favorite park bench using an old Olympus film camera. Back at his apartment, he’s got boxes and boxes of black-and-white photos of the same spot, every one of them unique. Subtle shifts of the light and swaying branches in the breeze make similar snapshots strikingly different every time. Indeed, the whole concept behind komorebi is that it can exist only in a moment, never to be repeated. “Next time is next time,” Hirayama’s fond of saying, “Now is now.”

Although I would disagree with Burns slightly because there is an English term for something related to komorebi and that is crown shyness, the phenomena where trees grow in such a way that their branches keep from touching one another creating a canopy of closeness yet also distance. Indeed, I would argue that crown shyness expresses more of what the movie is about than komorebi.
A key question that divides reviewers is whether Hirayama is happy or content. The standard interpretation is that he has found, as Davis puts it, “beauty in the routine,” stopping to smell the roses. Yes, that is one aspect, but the routine is also a narcotic for the lost. Hirayama is estranged from his family. Barkeeps like him but all his relationships are superficial. He plays a game with a “friend” he never meets—distance and disconnection are everywhere.. In two scenes he finds meaning and joy in looking after a child but in both these scenes the child’s mother quickly rips the child away. Hirayama’s work partner disappears in the second half of the film. He almost makes connections with three women but in each case, crown shyness intervenes. He takes pride in his work but is operating well below his ability. He is isolated, alone, and without someone else to share a life, he is incomplete.
There are great scenes and music in Perfect Days, including a beautiful scene in which a Japanese hostess (Sayuri Ishikawa) sings House of the Rising Sun.
Billy Joel: And So It Goes (HBO) — 52nd Street was one of my favorite albums as a youth and it was fun to revisit his career. Billy Joel’s first wife, Elizabeth Weber, was the muse for many of his early songs including Big Shot and Stiletto:
She cuts you hard, she cuts you deepShe’s got so much skillShe’s so fascinatingThat you’re still there waitingWhen she comes back for the killYou’ve been slashed in the faceYou’ve been left there to bleedYou want to run awayBut you know you’re gonna stay‘Cause she gives you what you need
She is indeed, fascinating! Wow. Even today, she comes across as formidable.
I thought a lot about genetics while watching And So It Goes. Joel’s father was a classical musician, though his only notable comment on Billy’s playing was to knock him unconscious for taking too much liberty with a piece. The father left when Billy was eight. Not much nurture. Years later, they reunite in Vienna—where Joel discovers he has a half-brother, Alexander Joel, a successful pianist and conductor.
Joel grew up poor, but his paternal grandfather had been a wealthy Jewish businessman in Germany until the Nazis forced him out. His mother, Rosalind, was also musical, but her primary inheritance may have been bipolar disorder. Joel’s mental health struggles are never explicitly named in the documentary, but the signs are everywhere: an early suicide attempt, alcoholism, repeated motorcycle and car crashes of a self-destructive nature. The emotional cycles also help explain the pattern of intense, short-lived marriages to beautiful and accomplished women—Weber, Christie Brinkley, Katie Lee, and Alexis Roderick. In his highs, he was irresistible. In his lows, unbearable. He goes to extremes.
Critics didn’t always love Joel’s music, but his catalog has become part of the American songbook. Proof of something Tyler and I often discuss, the power of simply keeping going.
Design Your Own Rug!
For my wedding anniversary, I designed and had hand-woven in Afghanistan a rug for my microbiologist wife. The rug mixes traditional Afghanistan designs with some scientific elements including Bunsen burners, test tubes, bacterial petri dishes and other elements.

I started with several AI designs, such as that shown below, to give the weavers an idea of what I was looking for. Some of the AI elements were muddled and very complex and so we developed a blueprint over a few iterations. The blueprint was very accurate to the actual rug.

I am very pleased with the final product. The wool is of high quality, deep and luxurious, and the design is exactly what I intended. My wife loves the rug and will hang it at her office. The price was very reasonable, under $1000. I also like that I employed weavers in a small village in Northern Afghanistan. The whole process took about 6 months.
You can develop your own custom rug from Afghanu Rugs. Tell them Alex sent you. Of course, they also have many beautiful traditional designs. You can even order my design should you so desire!
A household expenditure approach to measuring AI progress
Often researchers focus on the capabilities of AI models, for instance what kinds of problems they might solve. Or how they might boost productivity growth rates. But a different question is to ask how they might lower cost of living for ordinary Americans. And while I am optimistic about the future prospects and powers of AI models, on that particular question I think progress will be slow, mostly though through no fault of the AIs.
If you consider a typical household budget, some of the major categories might be:
A. Rent and home purchase
B. Food
C. Health care
D. Education
Let us consider each in turn. Do note that in the longer run AI will do a lot to accelerate and advance science. But in the next five years, most of those advances may not be so visible or available. And so I will focus on some budgetary items in the short run:
A. When it comes to rent, a lot of the constraints are on the supply side. So even very powerful AI will not alleviate those problems. In fact strong AI could make it more profitable to live near other talented people, which could raise a lot of rents. Real wages for the talented would go up too, still I would not expect rents to fall per se.
Strong AI might make it easier to live say in Maine, which would involve a de facto lowering of rents, even if no single rental price falls. Again, maybe.
B. When it comes to food, in some long run AI will genetically engineer better and stronger crops, which in time will be cheaper. We will develop better methods of irrigation, better systems for trading land, better systems for predicting the weather and protecting against storms, and so on. Still, I observe that agricultural improvements (whether AI-rooted or not) can spread very slowly. A lot of rural Mexico still does not use tractors, for instance.
So I can see AI lowering the price of food in twenty years, but in the meantime a lot of real world, institutional, legal, and supply side constraints and bottlenecks will bind. In the short run, greater energy demands could well make food more expensive.
C. When it comes to health care, I expect all sorts of fabulous new discoveries. I am not sure how rapidly they will arrive, but at some point most Americans will die of old age, if they survive accidents, and of course driverless vehicles will limit some of those too. Imagine most people living to the age of 97, or something like that.
In terms of human welfare, that is a wonderful outcome. Still, there will be a lot more treatments, maybe some of them customized for you, as is the case with some of the new cancer treatments. Living to 97, your overall health care expenses probably will go up. It will be worth it, by far, but I cannot say this will alleviate cost of living concerns. It might even make them worse. Your total expenditures on health care are likely to rise.
D. When it comes to education, the highly motivated and curious already learn a lot more from AI and are more productive. (Much of those gains, though, translate into more leisure time at work, at least until institutions adjust more systematically.). I am not sure when AI will truly help to motivate the less motivated learners. But I expect not right away, and maybe not for a long time. That said, a good deal of education is much cheaper right now, and also more effective. But the kinds of learning associated with the lower school grades are not cheaper at all, and for the higher levels you still will have to pay for credentialing for the foreseeable future.
In sum, I think it will take a good while before AI significantly lowers the cost of living, at least for most people. We have a lot of other constraints in the system. So perhaps AI will not be that popular. So the AIs could be just tremendous in terms of their intrinsic quality (as I expect and indeed already is true), and yet living costs would not fall all that much, and could even go up.
The Rising Cost of Child and Pet Day Care
Everyone talks about the soaring cost of child care (e.g. here, here and here), but have you looked at the soaring cost of pet care? On a recent trip, it cost me about $82 per day to board my dog (a bit less with multi-day discounts). And no, that is not high for northern VA and that price does not include any fancy options or treats! Doggie boarding costs about about the same as staying in a Motel 6.
Many explanations have been offered for rising child care costs. The Institute for Family Studies, for example, shows that prices rise with regulations like “group sizes, child-to-staff ratios, required annual training hours, and minimum educational requirements for teachers and center directors.” I don’t deny that regulation raises prices—places with more regulation have higher costs—but I don’t think that explains the slow, steady price increase over time. As with health care and education, the better explanation is the Baumol effect, as I argued in my book (with Helland) Why Are the Prices So Damn High?
Pet care is less regulated than child care, but it too is subject to the Baumol effect. So how do price trends compare? Are they radically different or surprisingly similar? Here are the two raw price trends for pet services (CUUR0000SS62053) and for (child) Day care and preschool (CUUR0000SEEB03). Pet services covers boarding, daycare, pet sitting, walking, obedience training, grooming but veterinary care is excluded from this series so it is comparable to that for child care.
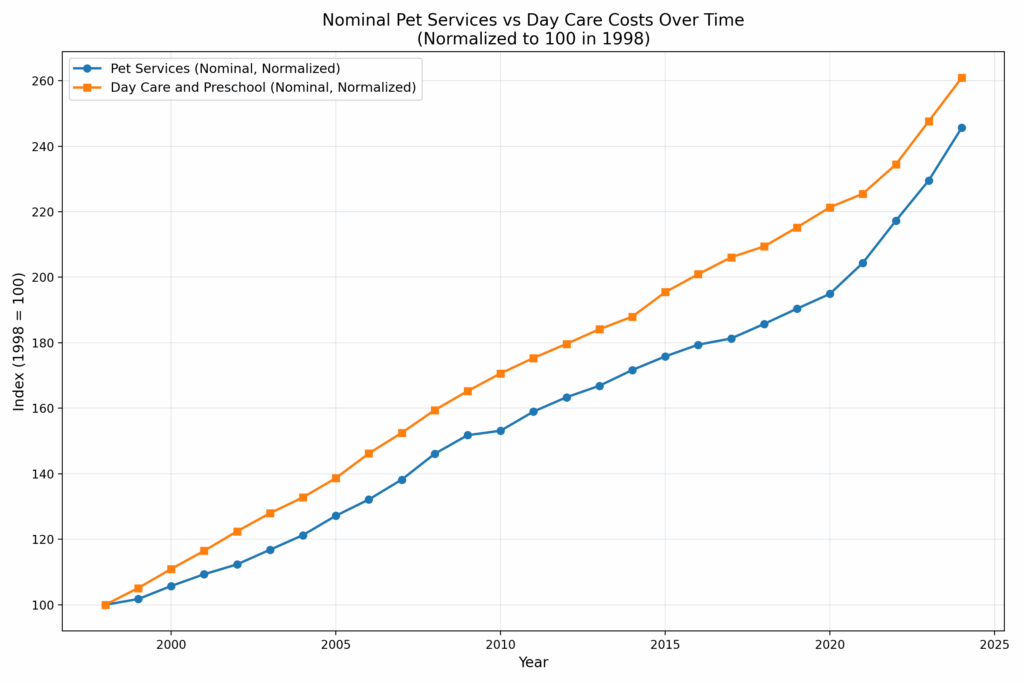
As you can see, the trends are nearly identical, with child care rising only slightly faster than pet care over the past 26 years. Of course, both trends include general inflation, which visually narrows the gap. When we normalize to the overall CPI, we get the following:
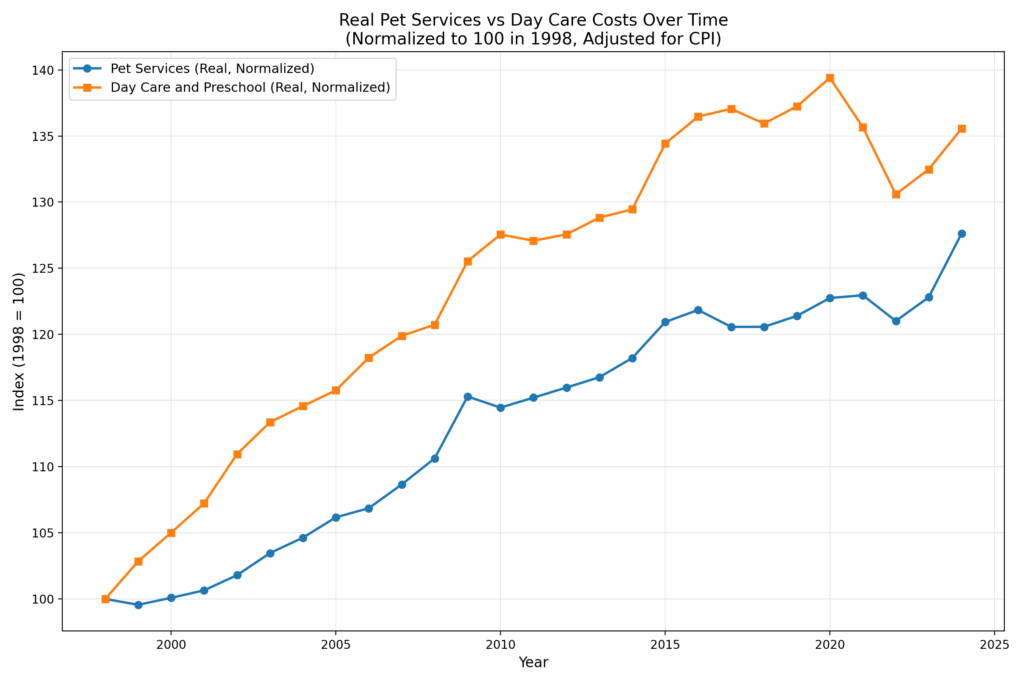
Over 26 years, the real (relative) price of Day Care and Preschool has increased 36%, while Pet Services have risen 28%. If regulation doesn’t explain the rise in pet care costs–and it probably doesn’t–then regulation probably doesn’t explain the rise in child care costs either. After all, child and pet care are very similar goods!
The similar rise in the price of child day care and pet day care/boarding is consistent with Is American Pet Health Care (Also) Uniquely Inefficient? by Einav, Finkelstein and Gupta, who find that spending on veterinary care is rising at about the same rate as spending on human health care. Since the regulatory systems of pet and human health care are very different this suggests that the fundamental reason for rising health care isn’t regulation but rising relative prices and increasing incomes (fyi this is also an important reason why Americans spend more on health care than Europeans).
Thus, my explanation for rising prices in child care and pet care is that productivity is increasing in other industries more than in the care industries which means that over time we must give up more of other goods to get child and pet care. In short, if productivity in other sectors rises while child/pet care productivity stays flat, relative prices must rise. Another way to put this is that to retain workers, wages in stagnant-productivity sectors must rise to match those in (equally labor-skilled) high-productivity sectors. That means paying more for the same level of care, simply to keep the labor force from leaving
But rising productivity in other sectors is good! Thus, I always refer to the Baumol effect rather than the “cost disease” because higher prices are not bad when they reflect changes in relative prices. As with education and health care the rising price of child and pet care isn’t a problem for society as whole. We are richer and can afford more of all goods. It can be a problem, however, for people who consume more than the average quantities of the service-sector goods and people who have lower than average wage gains. So what can we do? Redistribution is one possibility.
If we focus on the prices, the core problem is that care work is labor-intensive and labor has a high opportunity cost. One solution is to lower the opportunity cost of that labor. Low-skill immigration helps: when lower-wage workers take on support roles, higher-wage workers can focus on higher-value tasks. As I’ve put it, “The immigrant who mows the lawn of the nuclear physicist indirectly helps to unlock the secrets of the universe.” Same for the immigrant who provides boarding for the pets of the nuclear physicist.
Another solution is capital substitution—automation, AI, better tools. But care jobs resist mechanization; that’s part of why productivity growth is so slow in these sectors. Still, the basic truth remains: if we want more affordable day care—for kids or pets—we need to use less of what’s expensive: skilled labor. That means either importing more people to do the work, or investing harder in ways to do it with fewer hands.
Horseshoe Theory: Trump and the Progressive Left
Many of Trump’s signature policies overlap with those of the American progressive left—e.g. tariffs, economic nationalism, immigration restrictions, deep distrust of elite institutions, and an eagerness to use the power of the state. Trump governs less like Reagan, more like Perón. As Ryan Bourne notes, this ideological convergence has led many on the progressive left to remain silent or even tacitly support Trump policies, particularly on trade.
“[P]rogressive Democrats like Senator Elizabeth Warren have chosen to shift blame for Trump’s tariff-driven price hikes onto large businesses. Last week, they dusted off—and expanded—their pandemic-era Price Gouging Prevention Act. While bemoaning Trump’s ‘chaotic’ on-off tariffs, their real ire remains reserved for ‘greedy corporations,’ supposedly exploiting trade policy disruption to pad prices beyond what’s needed to ‘cover any cost increases.’
…The Democrats’ 2025 gouging bill is broader than ever, creating a standing prohibition against ‘grossly excessive’ price hikes—loosely suggested at anything 20 percent above the previous six-month average—but allowing the FTC to pick its price caps ‘using any metric it deems appropriate.’
…Instead of owning the pricing fallout from his trade wars, President Trump can now point to Democratic cries of ‘corporate greed’ and claim their proposed FTC crackdown proves that it’s businesses—not his tariffs—to blame for higher prices.
If these progressives have their way, the public debate flips from ‘tariffs raise prices’ to ‘the FTC must crack down on corporate greed exploiting trade policy reform,’ with Trump slipping off the hook.”
Trump’s political coalition isn’t policy-driven. It’s built on anger, grievance, and zero-sum thinking. With minor tweaks, there is no reason why such a coalition could not become even more leftist. Consider the grotesque canonization of Luigi Mangione, the (alleged) murderer of UnitedHealthcare CEO Brian Thompson. We already have a proposed CA ballot initiative named the Luigi Mangione Access to Health Care Act, a Luigi Mangione musical and comparisons of Mangione to Jesus. The anger is very Trumpian.
A substantial share of voters on the left and the right increasingly believe that markets are rigged, globalism is suspect, and corporations are the real enemy. Trump adds nationalist flavor; progressives bring the regulatory hammer. The convergence of left and right in attacking classical liberalism– open markets, limited government, pluralism and the basic rules of democratic compromise–is what worries me the most about contemporary politics.