Land Reclamation!
“Buy land,” they said, “they aren’t making any more.” But in fact, we used to make a lot of land. Half the land area of Boston, a quarter of Manhattan, and 15% of San Francisco were raised from the sea before 1970. Tyler has already pointed to Zigmund Forrest and Max Tabarrok’s piece on land reclamation in Works in Progress. Check it out, it’s an excellent piece.
But also don’t miss Connor Tabarrok’s historical overview of land reclamation featuring the ancient Iraqi city of Ur, Alexander the Great’s siege of Tyre, and the amazing flood tanks built under the city of Tokyo! Connor, a civil engineer by trade, points out that most land reclamation isn’t done to build cities with land fill but rather to create farmland through drainage:
In the lower 48 states, the US Fish and Wildlife Service estimates that wetlands covered 221 million acres in the 1780s and 104 million by the 1980s. That is roughly 117 million acres drained in two centuries, a loss rate the report puts at 60 acres an hour, sustained for 200 years. For comparison, the total urban footprint of the United States is around 70 million acres. America has drained substantially more wetland than it has built city, and nearly all of that drained land became farmland.
… The Dutch invented the modern polder and have spent eight centuries pushing back the North Sea, and the result is one of the densest, richest countries in Europe. Yet around two-thirds of the country’s dry land is farmland. Flevoland, the newest province, is 1,410 square kilometers reclaimed from the Zuiderzee in the 1950s and 60s, and it was laid out as an agricultural basin, not a city. The country with the most reclaimed land per person uses it to grow potatoes, graze dairy cattle, and ranks as the world’s second-largest agricultural exporter.
The other reason that we drained land historically was to get rid of mosquito-driven malaria and to improve sewage.
In the mid-1800s the land south and west of the Washington Monument was the Potomac Flats, a tidal marsh that collected the city’s sewage and exposed it to the sun twice a day. The stench reached the White House. In 1882 Congress appropriated $400,000 and the Army Corps of Engineers, under Major Peter Hains, began dredging the river’s shipping channels and pumping the mud onto the flats. The work created more than 600 acres of new ground and a Tidal Basin engineered to flush the Washington Channel with each tide. The Lincoln and Jefferson Memorials stand on that fill. So do the cherry trees, planted in 1912 on land that had been open water within living memory.
Much more of interest at the whole thing.
What to Watch and Not
 Spider Noir (Prime): I’ve had enough of the Marvel multiverse so I was worried about Spider-Noir. The writers, however, have written an excellent noir in the style of Raymond Chandler with Nicholas Cage channeling Humphrey Bogart. The Spiderman stuff is all there but it is appropriately embedded. There are some excellent lines. Most notably an inversion of the Spiderman motto that I won’t give here but you will know it when you hear it. Also many sharp one-liners:
Spider Noir (Prime): I’ve had enough of the Marvel multiverse so I was worried about Spider-Noir. The writers, however, have written an excellent noir in the style of Raymond Chandler with Nicholas Cage channeling Humphrey Bogart. The Spiderman stuff is all there but it is appropriately embedded. There are some excellent lines. Most notably an inversion of the Spiderman motto that I won’t give here but you will know it when you hear it. Also many sharp one-liners:
- Reilly: I don’t like surprises.
- Cat: I’ll remember that when your birthday rolls around.
Nicholas Cage does some Nicholas Cagey spidery things which I enjoyed. Watch it in black and white.
Project Hail Mary (Prime): I waited until this was streaming and I’m glad I did because it was disappointing.
The core problem is Ryan Gosling. He plays Ryland Grace, the genius scientist-hero but genius is something we are told, never shown. Indeed, the character with the best ideas in the film is Carl, Grace’s bodyguard/minder (played by Lionel Boyce)—they should have sent him to save the planet. Gosling has no intensity, and every choice he makes is to lighten and humorize. It’s a small thing, but it annoyed me to watch a scientist toss his instruments disdainfully. Andy Weir is a master at showing smart people grinding through hard problems—in the novel, Grace spends months learning to communicate with an alien. In the movie, Gosling dances.
This isn’t just miscasting. The whole adaptation is built to soften the book. The film cuts the desperation of the world, undercuts the ruthlessness of Stratt and instead adds a karaoke number and a trip to Home Depot (ha, ha, duct tape can solve everything!) Every change is away from high stakes intensity and toward charm and humor, a Disneyfied version of Weir. I have nothing against Gosling but we have lots of charming movies and I would like some competence porn.
The main virtue of PHM, in the end, is that it shows what a miracle The Martian was. Matt Damon knows how to play smart and intense, and he brought both to what I called the most Ayn Rand film in decades. There’s an old story—probably apocryphal—that Chuck Yeager was once asked what he’d do if his engine flamed out and he had sixty seconds before hitting the ground. He replied, “I’d spend the first fifty-nine seconds working on the engine.” Chuck Yeager had the right stuff. Matt Damon in The Martian has the right stuff. Ryan Gosling does not have the right stuff.
The Sheep Detectives (Prime): A delightful surprise! A flock of sheep solve a murder-mystery in a quaint English town; featuring Hugh Jackman and voices from Julia-Louis Dreyfus, Bryan Cranston, Patrick Stewart and others. Babe meets Knives Out. A family film but, as the best family films are, with some deep themes.
From Prediction Markets to Decision Markets and Beyond!
Arin Dube points to a great illustration of the power of prediction markets. Yesterday due to a new scandal the probability that Graham Platner would drop out of the Maine Democratic primary exploded from 9% to 96% (+87 percentage points). At the same time, the probability that the Democrats would win the election jumped by about 9 percentage points, from 54% to 63%. What does this tell you?
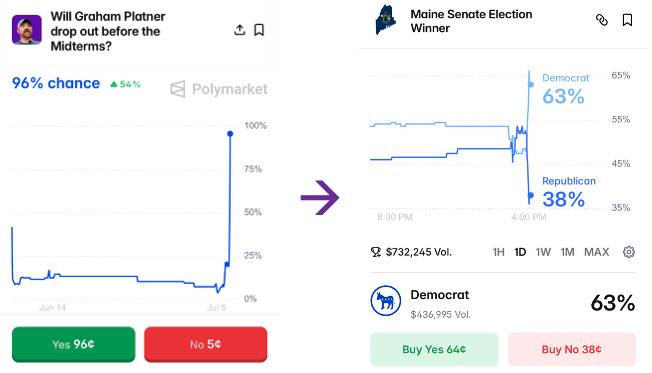 The market is signaling that Platner reduces the Democrats’ chances of victory. We can be more precise. If an 87-point increase in the probability of dropping out gets you 9 points of winning, then a 100% chance of dropping out implies a gain of 9/0.87 ≈ 10.3 percentage points.
The market is signaling that Platner reduces the Democrats’ chances of victory. We can be more precise. If an 87-point increase in the probability of dropping out gets you 9 points of winning, then a 100% chance of dropping out implies a gain of 9/0.87 ≈ 10.3 percentage points.
Thus the market’s best estimate is that Platner is reducing the Democrats’ chance of winning by about 10 percentage points (compared to an unknown replacement). That’s a pretty big number! Democrats should surely use this information to make better decisions.
Now, I have been a bit loose. We have implicitly assumed that the news mainly moved the probability of Platner dropping out, rather than independently changing the Democrats’ general-election prospects. The issue is we are trying to reverse engineer two conditional prices, P(win|drop) and P(win|stay), from one unconditional price, P(win), and its comovement with P(drop). It works pretty well here as an illustration but Robin Hanson’s idea is that we can do better yet by trading the conditionals instead of inferring them.
Hanson’s decision markets would run contracts of the form “pays $1 if Democrats win, conditional on Platner dropping out — bet refunded if he stays.” Plus the mirror contract conditioned on staying. The refund provision makes the price a conditional probability: a trader pricing the first contract doesn’t need any view on whether Platner drops out, only on how the race goes if he does. With this structure we would get cleaner estimates of the conditional probabilities–in this case whether the Democrats do better with Platner in or out–which is exactly what a decision maker needs.
We were able to plausibly reverse engineer our estimate because the market happened to move 87 points in a single day. But a decision market would have posted the number continuously, no scandal required. In other words, with decision markets in play, not just prediction markets, we could have seen how much Platner was costing the Democrats before the latest scandal hit—which is precisely when the information would have been most useful.
It’s been fun to see prediction markets catch on with the public but the world is still decades behind Hanson’s decision markets—let alone futarchy!
Capital Gains Can Be Labor Income
Zwick and Zidar argue that a substantial share of the decline in labor share can be accounted for by changing forms of pay, including pass-throughs and equtiy compensation. In particular, if an employee is paid in stock and that stock increases in value then the tax rules tend to count some of that as capital income (depending on when the capital gains occur) rather than as labor income. Zwick and Zidar point us to Human Capitalists for the details:
Human capitalists are corporate employees who receive significant equity-based compensation such as equity grants and stock options. These employees are partial owners of US firms, and in return for their human capital input, human capitalists accrue a share of firm profits through firm dividends and capital gains in addition to earning wages. We document the stylized facts describing the evolution of human capitalists’ income over time and across industries within the US manufacturing sector.1 Human capitalists have become an increasingly important class of corporate income earners. Due to measurement challenges, prior work has underestimated the importance of equity pay below the C-suite. Correctly measuring the total income of human capitalists substantially alters conclusions about changes in factor shares and technological complementarity.
Equity-based compensation represents 36% of compensation to human capitalists from 2010 to 2019 and constitutes a 7% share of value added in the manufacturing sector in 2019. Correctly accounting for the total income earned by high-skilled workers has a substantial effect on measured changes in labor shares over the modern era. The addition of equity pay to cash wages reduces the decline implied by the wage-only income share of value added in manufacturing since the 1980s by 32%. Without including equity pay, high-skilled labor’s share decreased from 17% in the 1980s to 11% in the most recent decade. The inclusion of equity-based compensation almost eliminates this decline. The high-skilled share of total labor income increases from one-third at the beginning of the 1960s to two-thirds in the 2010s when equity-based compensation is included.
See also my previous post The Labor Share Fell. So What?
How Britain Became as Poor as Mississippi
How Britain Became as Poor as Mississippi is a good piece in the Atlantic by Idrees Kahloon filled with colorful anecdotes of a nation in decline:
The health service now has to spend more money settling maternity-malpractice claims than it does on actually providing maternity care. Many Brits can neither obtain an appointment with a publicly funded dentist nor afford a private one; in a 2023 survey, one in 10 reported doing DIY dental work, in extreme cases extracting their own teeth or gluing broken crowns back together.
Incomes can be shockingly low: Junior doctors recently went on strike for the 15th time in three years over their salaries, which start at just £38,800; the median salary for British civil servants is £35,680. In April, amid the Iran conflict, the Daily Mail pounced on Prime Minister Keir Starmer for vacationing in Valencia, Spain, at what the tabloid described as a luxury hotel, costing £200 a night.
Americans are likely to come away a bit smug, especially as Independence Day approaches and Europeans are enjoying our giant stadiums and central air conditioning. Look deeper, however, and Britain’s story becomes more uncomfortable. Does this sound familiar?
Recent plans to transform the country have rested in no small part on High Speed 2, a superfast rail line intended to connect London with Birmingham, Leeds, and Manchester. But since HS2 was proposed, in 2009, its costs have tripled, to more than £100 billion. It is the most expensive rail line in the world. (A special structure to protect a rare bat species near the rail line in Buckinghamshire required 8,000 permits and was built at a cost of £216 million.) The most important sections of the proposed route have been lopped off. The rump line—going from Birmingham, Britain’s second-largest city, to not-quite-central London—may be finished by 2040…. HS2 has been delayed for so long that two swiftly built towers near the terminus now themselves look derelict and in need of demolition.
…Building infrastructure, or much of anything else, has become all but impossible in the United Kingdom. In addition to having the world’s most expensive (not yet built) train line, Britain also hosts the world’s most expensive (not yet built) nuclear-power plant, Hinkley Point C. Its environmental-impact assessment ran 31,401 pages; the plant will feature a £700 million “fish disco,” which will pulse sounds underwater to deter animals from its intake pipes.
Upon closer inspection, the United States looks a lot less like a shining city on a hill and a lot more like a declining Great Britain, appendaged with one or two dynamic sectors, most notably AI. The similarities are especially obvious in the retrograde solutions Britain has lumbered into, namely attacking immigrants and trade—Brexit being the equivalent of a high tariff regime. Nations in decline, like people, tend to lash out at others rather than deal with their real problems. Needless to say, neither immigrants nor trade explain Britain’s—or California’s—inability to build high-speed rail or other infrastructure.
It is discomforting to watch the birthplace of the Industrial Revolution, individual rights, and free speech—the nation that once built the railways, the steam engines, the factories that remade the world—lose the capacity to build much of anything, or even to tolerate people speaking their minds. In parallel, instead of dealing with our real problems—almost all of our creation—the right gets literally hysterical over symbolic culture-war questions like birthright citizenship, while the left nominates candidates with Marxist-Leninist sympathies. The abundance and progress movements are some of the few shining lights. It’s not too late. But Great Britain is a warning.
Rent Control: The Ceiling Trap
Rent control is in the news again. Check out my new website, Rent Control: The Ceiling Trap. Here is just one bit:
Norway abolished its rent control in 1982, and the economist Are Oust realized the newspapers had been quietly recording the whole experiment. He collected housing classifieds from Oslo’s Aftenposten from 1970 to 2008 and watched the market turn inside out.
Under rent control, Oslo’s listings pages looked nothing like a housing market. It was tenants who advertised, pleading their qualities to landlords — “housing wanted” ads outnumbered “housing for rent.” Ten to fifteen percent of those ads were placed by the tenant’s employer, vouching for them the way a bank vouches for a borrower. Tenants offered babysitting, gardening, snow-shoveling, and janitorial work on the side to sweeten the deal. Landlords, for their part, could demand a tenant of a particular gender, age, occupation, region of origin — some ads specified “strong Christian beliefs.” Deposits commonly ran to 50 or 60 months’ rent, occasionally 100 or more: tenants effectively lent the landlord the equity of the flat, interest free. And only about 20 percent of “for rent” ads dared print the rent, much of which would have been illegal.
Then the ceiling lifted. Within a few years the page flipped: landlords advertised to tenants, roughly 80 percent of listings printed an asking rent, the mega-deposits vanished, and the demands for snow-shoveling Christians of specified gender dwindled to nothing. The price went back to doing the rationing — so nothing else had to.
Check out the whole thing–it’s fabulous.
Politically Incorrect Paper of the Day: The US Racial Wealth Gap
Writing in the QJE, Derenoncourt, Kim, Kuhn, & Schularick argue that today’s black-white wealth gap can be explained by differences in initial conditions from over a hundred and fifty years ago, i.e. slavery. But there is an important, and glaring objection: in the age of immigration (1850–1924) millions of whites immigrated to the United States with essentially no wealth and yet they caught up to the “heritage” whites quite quickly and indeed today are richer than heritage whites.
Brian Marein collects and carefully analyzes the data:
Persistent racial wealth inequality in the United States is often attributed to the intergenerational transmission of historical wealth disparities. However, inferring the determinants of long-run inequality from group-level data is complicated by the arrival of 30 million Europeans during the Age of Mass Migration (1850–1924), who are by construction included in average white wealth despite having no direct claim to the wealth accumulated by earlier Americans. This paper accounts for this compositional change in the white population by documenting wealth dynamics among European immigrants and their descendants. Cash-on-arrival data show that immigrants began with substantial wealth deficits relative to the native-born. Yet by the late twentieth century, these deficits had closed, as indicated by comparisons between the descendants of later-arriving Southern and Eastern Europeans and those of longer-established Northwestern Europeans. This pattern implies rapid intraracial wealth convergence, in contrast to the slower convergence observed across racial groups. A stylized model shows that these differences can be largely accounted for by income. These findings demonstrate that large wealth disparities do not mechanically persist when groups have access to comparable economic opportunities.
If initial conditions don’t explain the wealth gap then the most likely explanation is an income and/or savings gaps. I am reminded of an earlier politically incorrect paper of the year by Nathaniel Hilger and see also my review of his book The Parent Trap.
Chloe vs. History
Excellent use of AI to create relatively accurate and realistic tours through history. Chloe is an engaging and personable guide–a fact of some importance.
Hat tip: Kevin Bryan.
Works in Progress: Grid Connection Auctions
The latest issue of Works in Progress is superb. Every article is interesting.
Chris Gillett points out something surprising: the US has plenty of electricity generation capacity ready to go, the problem is connecting it to the grid. Grid connection is complicated because on the grid, supply must equal demand at every moment in time. Even without speeding the process, however, we could get more power connected to the grid if we rationalized the ordering of connections.
The main flaw of the interconnection process is that it uses a first-come, first-served queue. This means that high-priority requests can spend years stuck at the back of the line behind other less important ones.
In essence, we have an airport congestion problem in which small Cessnas can bump 747s. Auctions for connection rights are the solution, as pointed out for airports by Vickrey and the classic paper by Rassenti, Smith and Bulfin. Gillett also emphasizes that some loads should be allowed to connect on a flexible basis: if a data center can disconnect or use backup power during the few peak hours each year, it should not have to wait years for firm service.
Gillett also has a very nice explanation of how market prices balance electricity from different sources:
Market prices signal to power plant developers about levels of supply and demand. In the same way, prices balance different energy sources based on the strengths and weaknesses of each. For instance, as more solar panels are built, the value (and therefore price) of power during the middle of the day, when the sun is shining most, adjusts downward. From December 2020 to September 2025, maximum solar output in ERCOT increased from 4 to 29.8 gigawatts. And from 2020 to 2025, the value of power at 1pm relative to the highest-priced hour decreased from 92.9 percent to 38.7 percent. As one technology type becomes overbuilt, prices reflect that and developers react accordingly.
The evolving daily price shape in response to the abundance of solar energy was a signal that the grid needed storage capacity, and power plant developers responded. From 2020 to October 2025, ERCOT went from having almost no battery storage to a combined battery discharge of 8.6 gigawatts. The same process has played out in California and many European markets.
New Business Formation is Surging–Again.
New business formation is surging–again.
Business formation first jumped in 2020 as the pandemic reorganized work, shopping and logistics. After the pandemic ended, business formation leveled off, but it did not return to its old path. It remained historically high. Moreover, in the past 18 months or so business formation has surged again. Registered Agents Inc tracks new Articles of Organization or Incorporation filed in the 50 states and they report:
Every month in 2026 has set a new formation record, including March, which stands as the highest single-month total in the history of the Business Formation Report. Through May, 2.9 million new businesses have been formed nationwide, the strongest five-month start on record.
Stripe Economics agrees and calls this the age of the solopreneur. Among businesses using Stripe, recent cohorts are reaching serious transaction volumes faster than earlier cohorts.
The share of businesses (not just solopreneurs) reaching $1 million in cumulative revenue within a year after going live on Stripe was roughly 30% higher for the 2025 cohort as it was for the 2023 cohort, and it was roughly 3x higher for the 2025 cohort than the 2019 cohort.
Furthermore, the trend is not just in the United States. France, where, as the story goes, they have no word for entrepreneur, has also seen business creation reach record levels, driven heavily by micro-entrepreneurs.
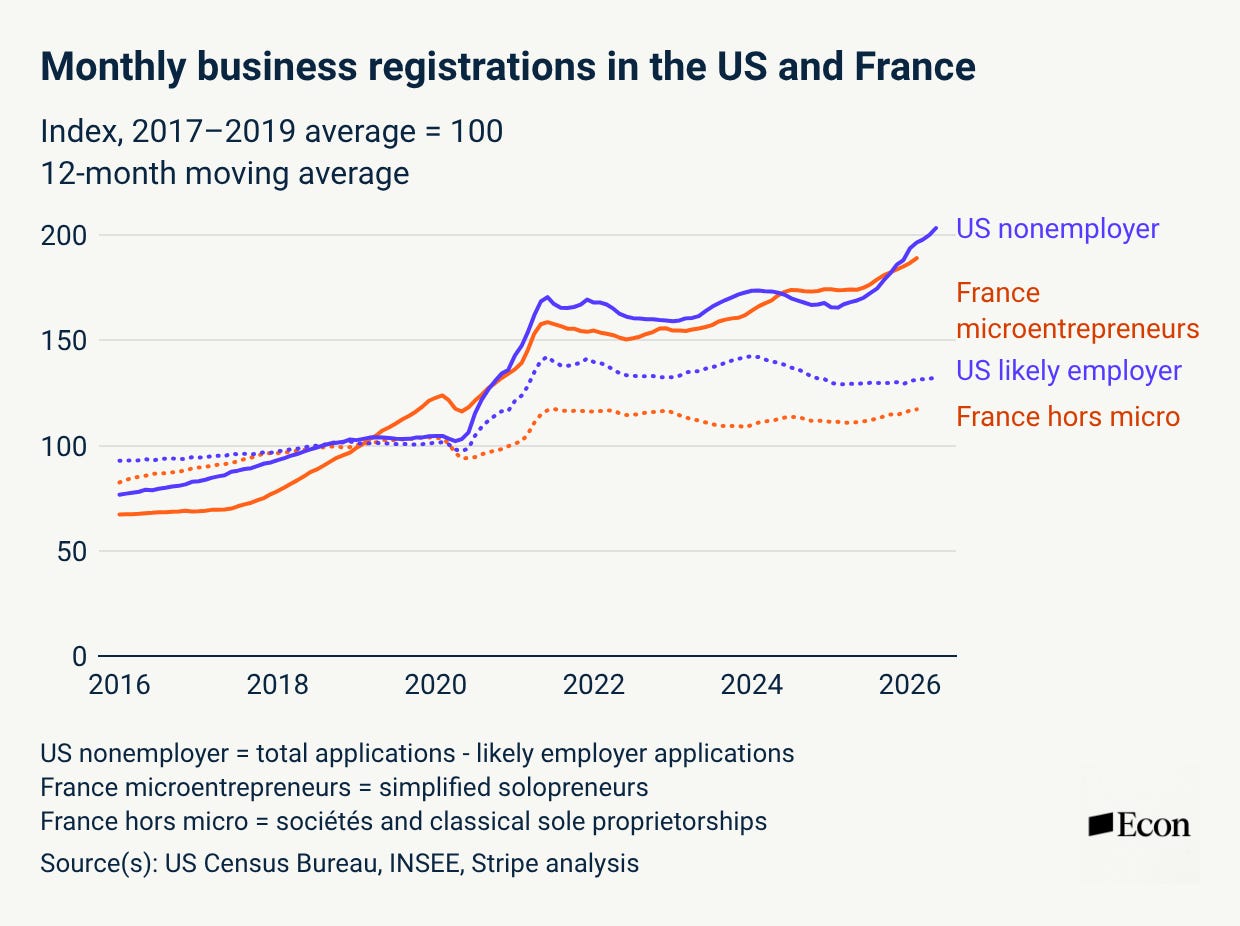
The most likely explanation is the devolution of power. A single person armed with Stripe, Shopify, cloud software, automated bookkeeping, and now AI can do what once required a small staff. Dynamism had been on a long secular decline, but we may now be seeing the early stages of an experimental economy—one in which far more people can test ideas, reach customers, and launch firms, some of which will grow very large, very fast.
Two Roads to Fast Clinical Trials, and the US Takes Neither
The HHS (FDA, NIH, ARPA-H and related agencies) is moving to speed clinical trials in what they are calling Operation TrialBlazer (kudos on the pun). The motivator, of course, is China:
China has made biotechnology a strategic national priority, systematically expanding its clinical research infrastructure with government backing, streamlined regulatory pathways, and sustained investment. In 2021, China’s global share of Phase 1 trials surpassed the United States’ share for the first time, a milestone that would have seemed unlikely just a decade earlier. And in 2024, China surpassed the United States in the total number of clinical trials registered, with over 7,100 registered, representing 39% of global trials…. For certain cutting edge modalities, including cell and gene therapy, radioligand therapy, and stem cell therapy, China uses investigator-initiated trials to provide additional flexibility, though with some tradeoffs around oversight and quality control. This means that drugs can move into human testing if a researcher has an interest and funding. In the U.S., comparable trials might wait years to start.
I am also pleased to see that they mention Australia, another advanced democracy, as a leader in clinical trial regulation:
Australia’s Clinical Trial Notification System allows trials to begin in fewer than 70 days after a final protocol is submitted, with regulatory approval granted in as little as 21 to 28 days and sites activated within 6 to 12 weeks.
Keep those comparisons in mind. Operation TrialBlazer proposes some good reforms such as CMC clarification. CMC is Chemistry, Manufacturing, and Controls–and it deals with the basics of manufacturing a drug. The FDA, however, is very risk averse and companies know that so they have often gone overboard in CMC: for example, proving stability of a formula at 6+ months when the trial is to last only a few weeks or documenting their full commercial manufacturing process before they even know if the drug works and knowing full-well that the process will be changed many times before a drug actually gets to market. In short, a lot of cost for very little benefit. The FDA is now clarifying that this kind of thing is not necessary. Good, that is low-hanging fruit. There are other good ideas as well.
But note what they are not proposing. Despite using China and Australia as exemplars they are not going down either path. Where China is fastest is in cell therapy, gene therapy, radioligand, and stem cell work and in these areas, China lets trials proceed on an investigator-initiated basis: as the TrialBlazer document puts it, a drug can move into humans “if a researcher has an interest and funding.” China then combines this open (or lax) front end (for these products) with an all-of-government industrial policy to accelerate winners.
The US is declining to go down that path. Ok, not my call, but I get it. But they are also declining to follow Australia. In Australia there is also no government prospective regulatory evaluation of most early-phase clinical trials. Under the Clinical Trial Notification (CTN) scheme, the sponsor submits their protocol package to a Human Research Ethics Committee (HRECs)–Australia’s IRBs–and once the ethics committee approves, the sponsor notifies the regulator, the Therapeutic Goods Administration (TGA), and pays a fee. The TGA does not read and clear the package before the trial starts. The roughly 21-to-28-day “approval” and sub-70-day start figures in the document are fast precisely because the regulatory step is not an evaluation. The government regulator stays out of the front end for most clinical trials, although in direct contrast with China it does step in for the highest risk biologicals. China has decided, high-risk, high-reward.
Australia does certify the certifiers, the HRECs. Europe uses a similar system for medical device approval. It’s a system proposed by former medical officer at the FDA Henry Miller and one I have long supported for the US. China is more laissez-faire.
The US architecture in contrast rests on the “gold standard” FDA reviews and the “FDA will retain full regulatory authority and decision-making.” In short, all of the TrialBlazer reforms are about making the gatekeeper faster, cheaper to prepare for, and less uncertain. None of it is about getting rid of the gatekeeper.
Addendum: Full disclosure, I did some consulting with ARPA-H on related work. See also my previous post on the a radical deregulatory approach, Montana’s SB535 and a Potential Biotech Renaissance in America
California’s Gay Certification Program
Chris Rufo and Austen Hufford have a good piece on California’s Gay Certification program. Yes, you read that right.
In 1986, Governor George Deukmejian signed Assembly Bill 3678, which required certain CPUC-regulated utilities to submit annual “plans” for buying goods and services from woman- and minority-owned companies. Two years later, CPUC created its “Supplier Diversity Program,” which would enforce the law and set contracting “goals” for large utilities.
Under a series of Democratic governors, the program has expanded to include gay-owned businesses. In September 2014, then-Governor Jerry Brown signed legislation requiring CPUC to recognize “LGBT-owned businesses” as eligible for supplier-diversity benefits. Five years later, Governor Gavin Newsom expanded the program further, “encouraging” other companies involved in the energy sector to award contracts to gay-owned firms.
…This scheme raises an obvious question: How does a business qualify as officially gay? Paperwork. Supplier Clearinghouse, a group that certifies firms for the CPUC program, features a list of qualifications linked on its website. Applicants can secure certification by providing a letter from an “LGBT organization” attesting to their sexual preferences; proof that a newspaper identified them as “LGBT”; or three letters from “personal contacts” written “on company letterhead” attesting to their homosexual orientation. Corporate officials who “falsely represent” their business as gay face up to a year in county jail.
So there you have it. Under the logic of ever increasing privileges for pretty much anyone except white males we now certify whether someone is gay or not.
This is an economics blog, however, so let’s turn from the culture war and ask, following Luke Froeb at Managerial Economics, what these set-asides cost the taxpayer:
A set-aside moves price through two separate channels, and they push the same direction.
- First, it shrinks the number of bidders, so the second-lowest cost is higher (or the second-highest value is lower).
- Second, the set-aside bidders themselves may be higher-cost or lower-value than the bidders they replace.
Both channels move price against the government….The lesson applies to California. Fewer, weaker bidders mean a worse deal for the government.
Brannman and Froeb estimate that set asides for small businesses reduce revenues in timber auctions by 15%, a substantial amount.
Addendum: It is worth noting that optimal auction theory tells us that it can sometimes be in the seller’s interest to handicap a strong bidder in order to make them increase their bids. Thus, in theory, an “affirmative action” program (not a set-aside) that deemed a bid from a minority firm as say 5% higher (so a minority bid at 100 can beat a non-minority bid at 104) could raise revenues. Note, however, that this optimal auction story only works when the minority firm loses the bid! In practice, even these sorts of schemes are money losers for the taxpayer.
Cuba
Some of the most impactful measures announced by Cuba’s Prime Minister Manuel Marrero Thursday include allowing:
- Private and foreign capital to purchase and sell fuel
- The creation of private corporate banking
- Private business owners to own more than one company and hire more than 100 workers
- Private businesses in agriculture and tourism
- Tourism property sales, evaluated case-by-case, for Cubans resident in the country and abroad
- Foreign investors to hire workers directly
- Foreign investment in Old Havana and other tourist spots, in state telecom ETECSA data centers, mobile networks, and other digital infrastructure
- The extension of surface rights up to 99 years and leases up to 50 years for foreign investments
- Real estate development in tourism
- Farmland lease rights for an “indefinite period”
- Wholesale and retail trade without limits by foreign entities
- The sale of state assets and state companies’ shares to the private sector and foreign companies.
Taken together, the reforms proposed significantly expand the private sector six decades after Cuba’s communist leaders forbade all private business—even frita stands— and adopted a centrally planned economy model that ended up ruining the country and dragging Cubans into a severe humanitarian crisis. Currently, the government is in such dire straits that it is even seeking to transfer the management of the country’s zoos and aquariums to private hands, another announced change.
Colorado’s Funeral Mistake
Today about a quarter of the US workforce are required to have a license to work in their chosen profession, up from just 5 percent in 1950. Almost always the trend has been to add occupational licensing over time, but in 1983 Colorado did something unusual: it delicensed funeral service workers such as funeral directors. Brandon Pizzola and I analyzed what happened in our 2017 paper, Occupational licensing causes a wage premium: Evidence from a natural experiment in Colorado’s funeral services industry.
What we found was that delicensing reduced wages, reduced prices, and caused a shift towards cremation rather than the more expensive mortuary services preferred by funeral directors. Here’s a key figure.
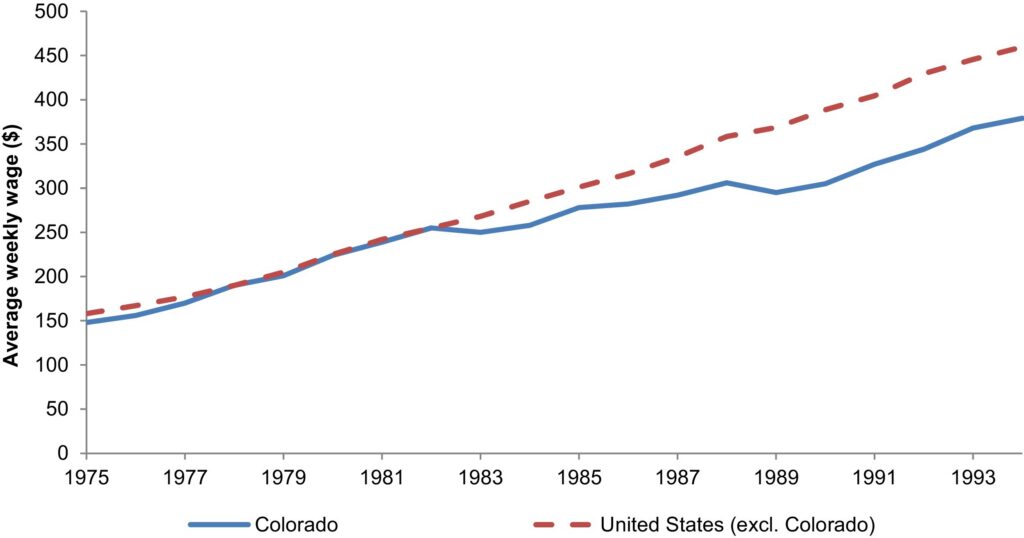
But that is not the end of the story. In 2023 a series of gruesome abuses came to light involving the sale of body parts, rotting bodies, and worse. Newspapers repeatedly noted that Colorado was the only state not to license funeral service workers. As a result, Colorado is relicensing funeral service workers as of 2027.
The problem is that there is no evidence that abuses were worse in Colorado. It’s easy to find similar abuses—including sexual abuse of corpses—in states with heavy licensing. Pizzola and I didn’t examine the rate of necrophilia among funeral workers in our paper (silly us), but we did cite the following:
A recent US government review of occupational licensing concluded that “the empirical research does not find large improvements in quality or health and safety from more stringent licensing” (CEA, 2015). Similarly, Colorado revisited their decision in a 1990 sunrise review that considered reinstating occupational licensing. The Colorado Department of Regulatory Agencies found that since the 1983 occupational delicensing: (1) “there had been incidents of malpractice within the profession but no widespread pattern of abuse,” (2) “[a]llegations of significant threats to the public health, safety and welfare perpetrated by the death care industry in Colorado regarding the improper disposal of human or infectious wastes had not been supported by verifiable evidence,” and (3) “claims that the public in Colorado had suffered or might suffer significant detriment due to a lack of trained mortuary science practitioners caused by the abolition of the Board were unsupported” (Colorado Department of Regulatory Agencies, 2007).
Moreover, the licensing requirements—mandating various hours of training and so forth—have very little to do with the types of abuses that generated public support for relicensing. How many hours of “don’t have sex with corpses” training is required? And the funeral director in the worst Colorado case was in fact sentenced to 40 years in jail. Isn’t that incentive enough?
People want what cannot be guaranteed: good behavior in all circumstances. And they will reach for a licensing regime if it promises that, even when such promises are empty.
The Shingles Vaccine Reduces Dementia
In 2023 in Can the Shingles Vaccine Prevent Dementia? I wrote:
A new paper provides good evidence that the shingles vaccine can prevent dementia, which strongly suggests that some forms of dementia are caused by the varicella zoster virus (VZV), the virus that on initial infection causes chickenpox.
We now have three more studies–from America, Australia and Canada–that find similar results using large numbers and credible research designs. Thus, I think we can up this to the Shingles vaccine reduces dementia.
Eric Topol summarizes the new evidence and writes:
If you are 50+ and have not gotten Shingrix vaccinated, you may want to consider that. You get protection vs Shingles (which can be dreadful), slowing of your biological aging (by methylation and RNA metrics), and ~20% reduction of dementia, predominantly related to Alzheimer’s disease. All of this benefit is magnified in women compared with men, but 3 of the studies showed some reduction of dementia in men. As a tradeoff, men appear to derive more cardiovascular benefit, but that evidence is not as compelling as protection from dementia from natural experiments.